
Les points clés à garder avant de construire un extracteur
- Une API officielle reste presque toujours plus stable qu’un parsing HTML.
- Le scraping devient pertinent quand l’information n’est pas exposée autrement ou quand l’API est incomplète.
- Un backend solide sépare récupération, parsing, normalisation et stockage.
- Le code HTTP 429, les changements de structure et les protections anti-bot sont les causes les plus fréquentes de panne.
- En France, la conformité et la protection des données ne sont pas accessoires si des données personnelles peuvent apparaître.
Ce qu’un extracteur web fait réellement
Je fais toujours une distinction nette entre découvrir des pages et en extraire la substance. Le crawling sert à repérer des URL; le scraping, lui, lit le contenu déjà connu pour en sortir des champs utiles comme un prix, une date, un titre, un identifiant produit ou un statut. Cette nuance paraît académique, mais elle aide à choisir la bonne architecture dès le départ.
En pratique, un extracteur web est un programme qui enchaîne quatre gestes: récupérer une ressource, analyser sa structure, isoler les données pertinentes, puis les remettre dans un format exploitable par une API interne, une base ou une file de traitement. Là où beaucoup de projets échouent, c’est quand on confond la réussite d’un test manuel avec la robustesse d’un flux de production.
| Approche | Quand je la choisis | Points forts | Limites |
|---|---|---|---|
| API officielle | Quand le site expose déjà les données par contrat | Format stable, authentification claire, pagination explicite, maintenance plus simple | Quotas, champs parfois incomplets, accès parfois payant ou restreint |
| Scraping HTML | Quand aucune API utile n’existe ou que l’API est trop pauvre | Souple, souvent rapide à prototyper, bonne couverture des pages publiques | Fragile face aux changements HTML, sensible au rate limiting et aux protections anti-bot |
| Navigateur headless | Quand le contenu dépend fortement du JavaScript | Permet d’exécuter la page comme un vrai navigateur | Plus lourd, plus lent, plus coûteux à opérer et rarement mon premier choix |
Quand une équipe me demande par où commencer, je réponds presque toujours: partez de la source la plus stable, pas de la plus spectaculaire. C’est précisément là que la question de l’API devient centrale.
Quand une API vaut mieux qu’un scraping HTML
Si une API officielle existe, je la privilégie sans hésiter. Elle donne un contrat de données plus lisible, une pagination mieux définie, des limites de charge explicites et souvent une authentification plus propre. Pour un backend, cela change tout: on peut versionner les appels, gérer les erreurs de manière cohérente et éviter de dépendre d’un HTML qui évolue sans prévenir.
Le scraping reste utile, mais il doit être justifié. Je le garde pour les cas où l’information n’est pas exposée autrement, où l’API est incomplète, ou quand il faut agréger des données publiques que le site ne met pas à disposition dans un format exploitable. En revanche, je n’utilise jamais le scraping pour contourner une restriction d’accès ou pour remplacer un canal prévu par le fournisseur.
| Critère | API | Scraping HTML |
|---|---|---|
| Stabilité | Élevée | Moyenne à faible |
| Coût de maintenance | Plutôt bas | Souvent élevé |
| Temps de mise en route | Variable, parfois rapide | Souvent très rapide pour un prototype |
| Dépendance au frontend | Faible | Forte |
| Intégration backend | Très propre | À normaliser sérieusement |
Je vois le bon arbitrage assez simplement: si les données sont disponibles par API, je pars de là; si elles ne le sont pas, je construis un pipeline de scraping minimal, explicable et surveillable. Une fois cette décision prise, le vrai sujet devient l’architecture backend.
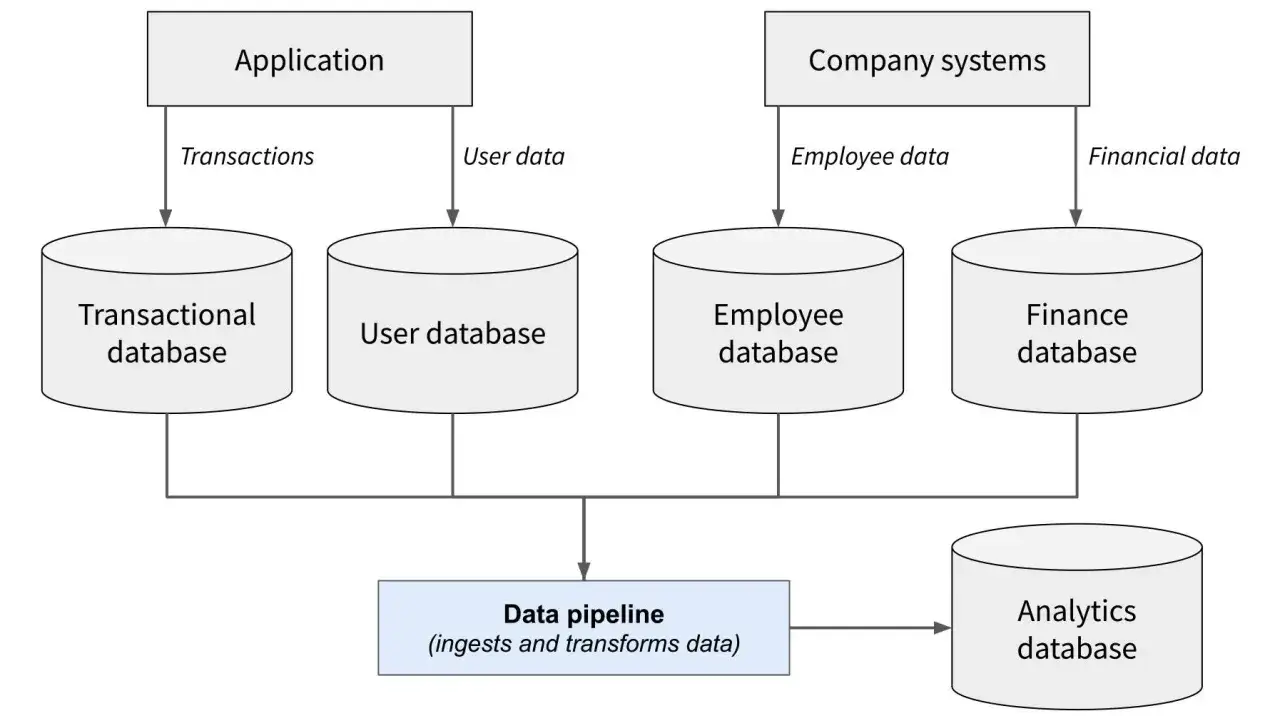
Je construis un pipeline backend en quatre couches
Un extracteur fiable n’est pas un script isolé. C’est un petit système, avec des responsabilités séparées. J’aime le découper en quatre couches: collecte, parsing, normalisation et stockage. Ce découpage évite de mélanger la logique de récupération, la logique métier et les contraintes de persistance.
Collecte
La collecte est la couche qui interroge le site ou l’API. Je la fais tourner dans un worker ou une file de tâches, jamais dans une boucle brute qui frappe le site sans pause. Quand le serveur répond trop vite par un code 429, je ralentis au lieu d’insister. Un en-tête de type Retry-After est un signal utile: il indique combien de temps attendre avant de relancer une requête.
Je garde aussi un identifiant clair dans le champ User-Agent, j’utilise des requêtes conditionnelles quand c’est possible, et je limite le volume par domaine. Sur un site qui change souvent, un peu de discipline au niveau réseau évite beaucoup d’incidents plus tard.
Parsing
Le parsing consiste à lire le HTML, le JSON embarqué ou parfois le JSON-LD pour en sortir les bons champs. Je préfère les sélecteurs simples et stables aux chaînes de dépendances trop fragiles. Quand je peux récupérer directement une réponse JSON issue d’un appel public prévu par l’application, je le fais: c’est souvent plus propre que de reconstruire un arbre DOM à la main.
Normalisation
C’est la couche que beaucoup de projets sous-estiment. Une date n’est pas seulement une date: elle peut être en format local, dans un fuseau horaire différent, ou contenir du texte parasite. Un prix peut inclure une devise, une taxe ou une variation régionale. Ici, je transforme tout en modèles cohérents, j’unifie les unités et je supprime les doublons.
Lire aussi : Authentification Flask - La méthode propre et sécurisée
Stockage
Pour les données hétérogènes, je stocke souvent d’abord le brut dans une base document ou dans un espace d’archivage, puis je dérive une version normalisée pour l’usage métier. Une base NoSQL est pratique quand les champs varient d’un site à l’autre ou quand la structure évolue vite. En revanche, pour des usages analytiques ou des relations bien définies, une base relationnelle reste souvent plus lisible. Je privilégie l’hybride: brut pour l’audit, normalisé pour l’exploitation.
Avec cette organisation, un changement de page ne casse pas tout le système. Il casse une couche précise, et c’est beaucoup plus gérable. Reste que même un pipeline bien pensé rencontre des fragilités récurrentes.
Les pièges techniques qui cassent les projets
Dans les projets de scraping, je retrouve toujours les mêmes sources de panne. Elles ne sont pas spectaculaires, mais elles sont tenaces: structure HTML qui change, contenu chargé en JavaScript, pagination mal comprise, ou anti-bot plus agressif qu’attendu. Le problème n’est pas seulement de récupérer les données une fois; c’est de les récupérer encore demain, sans intervention permanente.
| Symptôme | Cause probable | Réflexe utile |
|---|---|---|
| Champs vides alors que la page semble correcte | Sélecteur CSS devenu obsolète ou contenu injecté par JavaScript | Vérifier la source réseau, tester un endpoint JSON, réduire la dépendance au DOM |
| Blocage après quelques dizaines de requêtes | Rate limiting, comportement perçu comme automatisé | Ralentir, répartir les requêtes, respecter le tempo du serveur |
| Résultats incohérents d’un run à l’autre | Variation de langue, devise, pagination ou tri par défaut | Fixer les paramètres d’entrée et normaliser avant stockage |
| Doublons massifs | Reprise de tâches sans clé d’idempotence | Créer une clé stable par ressource et dédupliquer à l’ingestion |
| Temps de réponse trop élevé | Navigateur headless utilisé là où un simple client HTTP suffirait | Réserver le headless aux pages réellement dynamiques |
Je ne compte plus le nombre de fois où un projet a tenté de “gagner” contre un site en multipliant les requêtes. C’est rarement une stratégie durable. Le bon réflexe consiste plutôt à observer les signaux du serveur, à traiter proprement les erreurs, et à ne pas confondre vitesse de prototypage et qualité d’exploitation.
Il y a aussi des points plus discrets, mais tout aussi pénibles: encodage de caractères mal géré, devise mal interprétée, contenu multilingue, ou balises générées différemment selon le pays. Un bon extracteur anticipe ces variations au lieu de les découvrir en production.
Tout cela reste secondaire si le cadre légal n’est pas clair. Et là, en France, il faut être précis.
Le cadre légal à ne pas traiter comme un détail
Quand des données personnelles peuvent être collectées, je ne raisonne jamais comme si “public” voulait dire “libre de tout cadre”. La CNIL rappelle que la collecte de données accessibles en ligne par moissonnage s’appuie généralement sur l’intérêt légitime, mais qu’elle doit être accompagnée de mesures additionnelles pour protéger les droits des personnes concernées. En clair: le fait que l’information soit visible ne suffit pas à justifier n’importe quel usage.
Concrètement, je garde plusieurs garde-fous. Je limite la collecte au strict nécessaire, je supprime rapidement ce qui n’est pas utile, je documente la finalité, et je fais attention aux données sensibles ou aux contenus qui touchent des personnes vulnérables. Je respecte aussi les protections techniques et les signaux d’opposition, au lieu d’essayer de les contourner.
- Je collecte uniquement les champs utiles au cas d’usage.
- Je garde une trace de la source et de la date d’extraction.
- Je supprime les données hors périmètre dès que possible.
- Je n’essaie pas de passer au travers d’un CAPTCHA ou d’une protection explicite.
- Je vérifie les conditions du site et je traite robots.txt comme un signal sérieux, pas comme un fichier décoratif.
Le point le plus important est simple: plus le projet manipule des données personnelles, plus la discipline technique et documentaire doit être forte. Une extraction rapide peut paraître rentable au début; un projet qui n’anticipe ni les droits des personnes ni la sécurité devient vite coûteux à corriger.
La stratégie qui évite le plus de dette technique
Si je devais résumer ma méthode, je dirais que je pars toujours du besoin réel, pas de l’outil. Pour une récupération ponctuelle, une API ou un export manuel peut suffire. Pour une veille récurrente, un extracteur léger, cadencé et bien observé est souvent le bon compromis. Pour des volumes importants ou des pages très dynamiques, je passe à une architecture plus robuste, avec file de tâches, retries, métriques et stockage séparé du brut.
Mon critère final est très simple: la meilleure solution n’est pas celle qui extrait le plus vite, mais celle qu’on peut maintenir sans surprise. Si la source propose une API, je la privilégie. Si elle n’en propose pas, je construis un pipeline de scraping sobre, explicable et conforme. Et si le besoin est stratégique, je cherche souvent un canal de données plus stable avant de complexifier le backend.
En pratique, c’est cette discipline qui fait la différence entre un script fragile et un vrai composant de données. Quand le système est bien pensé, l’extraction devient un maillon fiable de l’application, pas une source permanente d’incidents.