
Dans un backend Symfony, l’enjeu n’est pas seulement de “parler à la base”, mais de garder un modèle métier lisible, des requêtes maîtrisées et des écritures fiables. Je vais donc aller à l’essentiel: comment Doctrine s’intègre au framework, comment je structure les entités et leurs relations, pourquoi les migrations comptent vraiment, et où les performances commencent à se dégrader dans une API.
Les points clés à garder en tête avant d’écrire la moindre requête
- Doctrine relie vos objets PHP à une base relationnelle, avec un EntityManager qui pilote le cycle de vie des entités.
- Les relations les plus utiles en pratique sont ManyToOne, OneToMany et ManyToMany, mais il faut les garder sobres.
- Les migrations sont la voie sûre pour faire évoluer le schéma, pas `schema:update` en production.
- Pour une API, les repositories doivent centraliser la logique de lecture au lieu de laisser les contrôleurs tout décider.
- Les problèmes les plus fréquents viennent du N+1, des grosses collections et des `flush()` trop larges.
- Quand le besoin devient du reporting, du bulk ou du SQL très spécifique, je sors volontiers de l’ORM pour passer par DBAL ou du SQL brut.
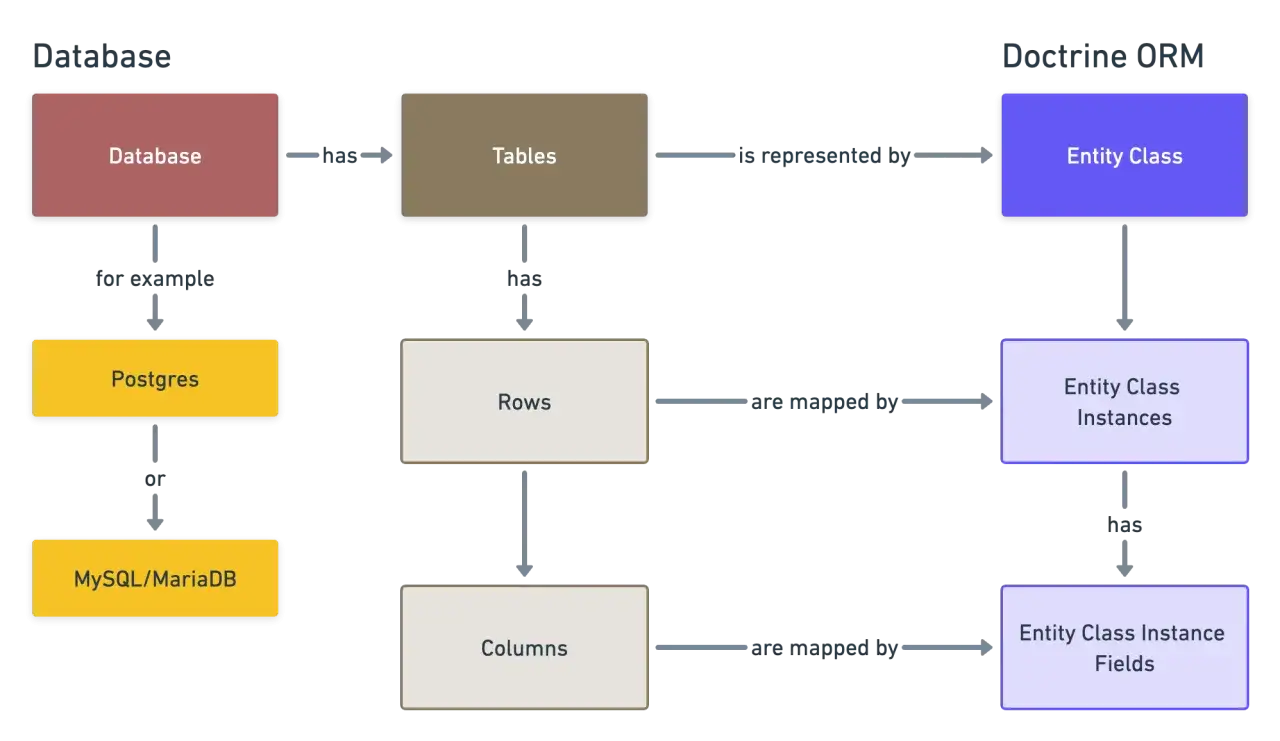
Comprendre ce que Doctrine apporte dans Symfony
Je pars d’un principe simple: Doctrine est utile quand je veux manipuler des objets métier sans transformer chaque opération en SQL manuel. Dans Symfony, le bundle Doctrine branche l’ORM et le DBAL au framework, ajoute des commandes console et donne une intégration propre avec le reste de l’écosystème. En clair, je peux créer, lire, modifier et supprimer des données avec un modèle orienté objet, tout en gardant la base relationnelle en dessous.
Le cœur du sujet, c’est le couple EntityManager et UnitOfWork. L’EntityManager gère le cycle de vie des entités, tandis que le UnitOfWork suit ce qui a changé jusqu’au flush(). C’est ce mécanisme qui permet à Doctrine de regrouper les écritures et de les envoyer en transaction cohérente, au lieu de multiplier les allers-retours vers la base.
Je recommande cette approche pour la majorité des CRUD métier, des backends applicatifs et des APIs classiques. En revanche, dès qu’on entre dans des traitements massifs, des rapports complexes ou des requêtes d’agrégation très spécifiques, l’ORM devient moins naturel. Cette limite n’est pas un défaut: c’est juste le bon signal pour choisir l’outil adapté, et c’est précisément ce que je détaille plus loin.
Une fois ce rôle bien posé, la vraie question devient la modélisation: quelles entités créer, et comment les relier sans fabriquer un graphe impossible à maintenir?
Modéliser les entités et les relations sans créer un graphe ingérable
La qualité d’un projet Doctrine se joue souvent ici. Je vois encore trop de schémas où chaque objet référence cinq autres objets “au cas où”. Doctrine sait gérer ça, mais votre code, lui, va le payer en complexité, en chargements inutiles et en bugs de synchronisation. La règle que j’applique est stricte: je garde les associations uniquement quand elles portent une vraie valeur métier.
La documentation Symfony insiste d’ailleurs sur un point que je partage: il vaut mieux limiter les relations et éviter les associations bidirectionnelles quand elles n’apportent rien. C’est plus simple à lire, plus simple à maintenir, et généralement plus rapide à exécuter.
| Relation | Quand je la choisis | Risque courant |
|---|---|---|
| ManyToOne / OneToMany | Le cas le plus fréquent: un produit appartient à une catégorie, un post appartient à un auteur. | Mal gérer le côté propriétaire de la relation et obtenir des mises à jour qui ne partent pas en base. |
| ManyToMany | Quand les deux côtés peuvent contenir plusieurs éléments de l’autre côté, par exemple tags et articles. | Transformer la table de jointure en fourre-tout et perdre la lisibilité du modèle. |
| OneToOne | Quand un profil, une adresse ou une configuration n’existe qu’une seule fois pour un objet donné. | Le surutiliser alors qu’un ManyToOne avec contrainte unique aurait suffi. |
Ce tableau n’est pas théorique: il évite les mauvais choix dès le départ. Dans une API, une relation trop large devient vite un problème de sérialisation, de performances et de logique métier. C’est pour cela que je choisis mes associations avant même de penser aux endpoints.
Quand le modèle est clair, je peux faire évoluer le schéma sans improviser. C’est là que les migrations prennent toute leur importance.
Faire évoluer la base proprement avec les migrations
Je déconseille de considérer les migrations comme une option décorative. Dans Symfony, elles sont la manière fiable de faire passer le schéma de l’état local à la production sans surprise. La documentation Symfony les présente explicitement comme l’alternative sûre à `schema:update`, et je suis d’accord: ce dernier est trop brut pour un environnement sérieux.
Mon flux de travail habituel est très simple:
- Je modélise ou ajuste l’entité avec
php bin/console make:entity. - Je génère le diff avec
php bin/console make:migration. - Je relis le fichier généré avant de l’exécuter.
- J’applique la migration avec
php bin/console doctrine:migrations:migrate.
Ce que je vérifie systématiquement, ce ne sont pas seulement les colonnes ajoutées ou supprimées, mais aussi les contraintes réelles sur les données existantes. Si je passe une colonne à NOT NULL, si je change une clé étrangère ou si j’introduis une valeur par défaut, je pense d’abord à la donnée déjà présente en base. C’est souvent là que les migrations cassent, pas dans le DDL lui-même.
Autre réflexe utile: pour les versions d’API ou les gros changements de modèle, je préfère plusieurs petites migrations à une grosse migration “propre sur le papier”. Les petites étapes sont plus faciles à relire, à corriger et à déployer. Et une fois ce socle en place, le vrai sujet devient la façon d’exposer les données proprement côté lecture.
Écrire des repositories utiles pour une API propre
Dans un backend API, je veux que les contrôleurs restent fins. Les contrôleurs devraient orchestrer la requête, appeler le bon service ou le bon repository, puis renvoyer une réponse. La logique de recherche, de tri, de pagination et de filtrage ne devrait pas se disperser dans dix endpoints différents.
Le repository est donc l’endroit naturel pour les requêtes métier. Je l’utilise pour encapsuler des intentions lisibles: “trouver les articles publiés récemment”, “charger les commandes d’un client”, “récupérer les ressources actives avec leurs dépendances utiles”. Ce n’est pas seulement une question de propreté du code; c’est aussi un moyen de centraliser les optimisations.
public function findPublishedRecent(int $limit = 20): array
{
return $this->createQueryBuilder('p')
->andWhere('p.publishedAt IS NOT NULL')
->orderBy('p.publishedAt', 'DESC')
->setMaxResults($limit)
->getQuery()
->getResult();
}Ce genre de méthode a deux avantages. D’abord, elle garde la requête lisible. Ensuite, elle permet de faire évoluer la stratégie d’accès aux données sans toucher au contrôleur ni au contrat API. Si demain j’ai besoin d’un join supplémentaire, d’un filtre par état ou d’un tri multi-critères, je sais où intervenir.
Pour une API, j’ajoute presque toujours une couche de précaution: je ne laisse pas la structure interne de l’entité décider seule de la forme de la réponse. Selon le cas, je passe par des groupes de sérialisation ou par des DTO dédiés. C’est particulièrement utile quand la forme d’écriture et la forme de lecture ne sont pas identiques.
Une fois les requêtes encapsulées, il reste le point qui finit par coûter le plus cher si on l’ignore: la performance.
Gérer les performances avant que la base ne devienne lente
Le problème de performance le plus fréquent avec Doctrine n’est pas “Doctrine est lent”, mais “Doctrine charge trop”. Le classique, c’est le N+1: une liste principale charge bien, puis chaque élément déclenche ensuite une requête supplémentaire pour ses relations. Sur dix éléments, cela reste discret; sur des centaines, cela devient visible très vite.
Je surveille aussi la taille des collections. Doctrine charge les associations de façon paresseuse par défaut, ce qui est pratique, mais une collection énorme peut coûter cher à initialiser. Pour des collections potentiellement volumineuses, le mode EXTRA_LAZY est une vraie aide: il permet de faire certaines opérations comme count() ou isEmpty() sans tout ramener en mémoire.
Sur les écritures en masse, je garde une règle très nette: l’ORM n’est pas l’outil naturel pour insérer, mettre à jour ou supprimer des milliers de lignes d’un coup. La documentation Doctrine recommande d’ailleurs le traitement par lots, avec des flush() fractionnés. Un point de départ raisonnable, souvent cité dans les exemples, est une taille de lot autour de 20, puis je l’ajuste selon la mémoire et le temps de réponse.
- Je limite les relations chargées dans les endpoints de liste.
- Je préfère une requête explicite à une cascade de chargements automatiques.
- Je désactive ou réduis le logger SQL pendant les batchs lourds.
- Je garde le
flush()court et ciblé, surtout dans les traitements longs. - J’évite les clés composites quand je peux les remplacer par un identifiant simple.
Le gain le plus important vient souvent de la discipline, pas d’une astuce magique. Quand je commence à voir trop de données circuler, je ne cherche pas d’abord à “optimiser Doctrine”; je réduis d’abord la quantité de travail que je lui demande. Et quand ce n’est toujours pas suffisant, je passe à l’outil suivant: DBAL ou SQL brut.
Savoir quand passer par DBAL ou du SQL brut
Il y a des cas où l’ORM est la bonne réponse, et d’autres où il devient un détour. Pour les flux métier classiques, Doctrine reste agréable. Pour les gros exports, les agrégations complexes, les requêtes très orientées lecture ou les opérations massives, je préfère souvent le DBAL ou du SQL brut, parce que je récupère un contrôle précis sur le plan d’exécution et sur le volume de données.
Je résume généralement le choix comme ça:
| Besoins | ORM Doctrine | DBAL ou SQL brut |
|---|---|---|
| CRUD métier standard | Très adapté | Possible, mais souvent inutilement verbeux |
| Requêtes de lecture avec filtres métier | Bon choix si le volume reste raisonnable | Utile si la requête devient très spécifique |
| Bulk insert, update, delete | Moins adapté | Meilleur choix |
| Reporting et agrégations lourdes | Souvent trop indirect | Plus simple à maîtriser |
| Optimisations très ciblées par SGBD | Limité par l’abstraction | Plus flexible |
Ce n’est pas un aveu d’échec de sortir de l’ORM. C’est une décision d’architecture raisonnable. La séparation entre accès objet et accès bas niveau existe justement pour ça, et la documentation Symfony la maintient clairement: Doctrine couvre très bien les bases relationnelles, tandis que l’accès bas niveau répond à d’autres contraintes. Dans un backend sérieux, je préfère ce découpage à une solution “tout ORM” qui devient fragile dès qu’on la pousse trop loin.
Le bon compromis, à mes yeux, consiste à garder Doctrine là où il accélère vraiment le développement, et à utiliser le SQL quand la forme de la donnée ou le volume rend l’objet moins pertinent. Cette frontière devient beaucoup plus facile à tenir si l’on a des règles de travail stables.
Ce que je garde pour un backend Symfony qui tient dans la durée
Si je devais condenser l’expérience en quelques réflexes, je dirais que Doctrine fonctionne très bien quand je reste sobre. Je limite les relations, je garde les entités concentrées sur le domaine, je passe les évolutions de schéma par des migrations relues, et je refuse de laisser les contrôleurs faire le travail du repository.
- Je privilégie des entités simples plutôt qu’un modèle surchargé.
- Je valide chaque migration comme si elle allait casser en production, parce que c’est souvent le cas si on la lit trop vite.
- Je traite les endpoints de lecture comme des requêtes à optimiser, pas comme des “listes d’objets à afficher”.
- Je ne garde pas en mémoire plus d’objets que nécessaire dans une même unité de travail.
- Je passe par un DTO quand la forme API ne correspond pas à la forme métier.
Le vrai bon usage de Doctrine n’est pas de tout faire avec lui, mais de l’utiliser là où il fait gagner du temps sans dégrader la maîtrise du backend. Si je devais retenir une seule chose, ce serait celle-ci: l’ORM est excellent pour structurer, moins bon pour masquer les coûts. Dès qu’on garde cette lucidité, Symfony et Doctrine deviennent un duo très solide pour construire une API maintenable, claire et capable de tenir la charge.