
WebRTC permet de faire circuler l’audio, la vidéo et parfois des données directement dans le navigateur, sans plugin et avec une latence adaptée aux échanges en direct. Pour une interface frontend, ce n’est pas seulement une API de plus : c’est un ensemble de choix techniques qui touchent la capture média, la négociation de connexion, la sécurité, la compatibilité navigateur et l’expérience utilisateur. Ici, je vais aller droit au but : ce que cette technologie apporte vraiment, comment elle s’assemble dans le navigateur et où se cachent les pièges qui font perdre du temps en production.
Les points essentiels à retenir avant d’intégrer le temps réel au front
- WebRTC gère le média et les échanges pair à pair, mais il ne remplace pas le signalement.
- Côté frontend, les briques les plus utiles sont
getUserMedia(),RTCPeerConnection,RTCDataChannelet parfoisgetDisplayMedia(). - HTTPS, permissions utilisateur et gestion des états sont indispensables dès le premier prototype.
- Pour un appel à plusieurs, l’architecture change vite : le mesh simple convient peu dès que le nombre de participants augmente.
- TURN n’est pas un détail : sans relais, certaines connexions échoueront derrière des réseaux d’entreprise, des NAT stricts ou des pare-feu.
- La qualité perçue dépend autant de l’UI et des fallbacks que de la connexion elle-même.
Ce que WebRTC change côté interface
Je vois souvent WebRTC comme une technologie qui déplace une partie du “temps réel” dans le navigateur lui-même. L’interface ne se contente plus d’afficher un flux : elle doit demander l’accès au micro ou à la caméra, vérifier les permissions, créer une connexion, écouter les événements réseau et réagir à chaque changement d’état. C’est ce qui la rend puissante, mais aussi plus exigeante qu’un simple chat en WebSocket.
Son intérêt est clair dans les cas où la latence compte vraiment : visioconférence, appel audio, assistance à distance, partage d’écran, collaboration en direct, ou encore transfert bidirectionnel de données entre deux onglets ou deux appareils. Le point important, côté produit, c’est que le navigateur sait transporter le média, mais pas décider avec qui parler ni quand raccrocher : cette logique-là vous appartient.
Autrement dit, je ne traite jamais WebRTC comme une surcouche “magique”. Je le traite comme un bloc technique qui exige un bon design d’interface, des messages d’erreur utiles et une architecture de signalisation propre. C’est cette différence qui sépare une démo impressionnante d’un produit stable.
Pour comprendre pourquoi, il faut regarder comment une session se met réellement en place dans le navigateur.
Comment une session se négocie dans le navigateur
Une connexion temps réel ne s’ouvre pas d’un seul geste. Le navigateur doit d’abord obtenir les médias locaux, puis échanger des informations de session avec l’autre pair, puis tester plusieurs chemins réseau avant de retenir celui qui fonctionne le mieux. C’est simple sur le papier, mais il y a plusieurs couches à faire cohabiter proprement.
Le rôle du signalement
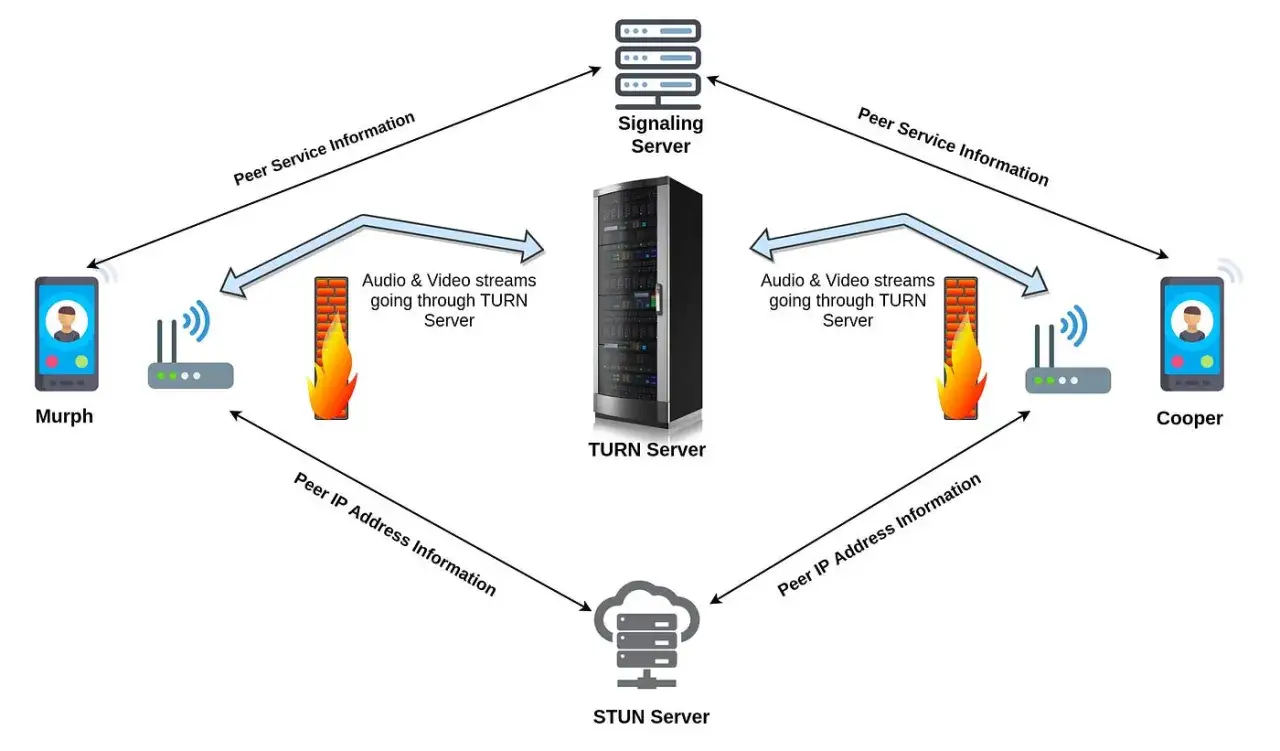
Le navigateur ne fournit pas le canal de signalement. En pratique, j’utilise presque toujours un serveur de signalement séparé, souvent via WebSocket, pour échanger l’offre, la réponse et les candidats ICE. Cette couche sert uniquement à faire se rencontrer les deux extrémités ; une fois la session établie, elle n’a plus besoin de porter le média lui-même.
ICE, STUN et TURN
ICE est le mécanisme qui cherche un chemin viable entre les deux navigateurs. STUN aide un client à comprendre sa position vue depuis Internet, tandis que TURN sert de relais quand la connexion directe échoue. Sans TURN, votre application peut fonctionner parfaitement chez vous et échouer chez un client en réseau d’entreprise. C’est un point que je vérifie tôt, pas après la mise en ligne.
Lire aussi : Balise HTML - Maîtrisez le temps de votre contenu
Les états que je surveille
Dans le frontend, je surveille au minimum signalingState, connectionState et les événements icecandidate, track et negotiationneeded. Ces signaux me disent si la session progresse, si elle se reconnecte ou si elle est en échec silencieux. Quand on les ignore, on finit avec une interface qui “semble” fonctionner alors que la session est déjà cassée.
Une fois cette mécanique comprise, le vrai sujet devient plus concret : quelles API du navigateur il faut vraiment maîtriser et comment les utiliser sans alourdir l’interface.
Les API frontend à maîtriser
Je préfère raisonner en briques fonctionnelles plutôt qu’en “grosse API” unique. Chacune a son rôle, son moment d’appel et ses contraintes de sécurité. En voici les principales.
| API | Ce qu’elle fait | Point d’attention |
|---|---|---|
navigator.mediaDevices.getUserMedia() |
Demande l’accès à la caméra et au micro pour créer un flux local. | Fonctionne en contexte sécurisé et déclenche un prompt utilisateur ; il faut prévoir l’échec et le refus. |
RTCPeerConnection |
Construit la session pair à pair, gère la négociation et le transport. | Demande une bonne gestion des états, du signalement et de la renégociation. |
RTCDataChannel |
Transporte des données arbitraires entre pairs. | Très utile pour le chat, la collaboration ou les messages de contrôle, mais ce n’est pas un backend de fichiers à lui seul. |
getDisplayMedia() |
Permet le partage d’écran, de fenêtre ou d’onglet. | L’utilisateur choisit explicitement la source ; il faut gérer l’arrêt du partage proprement. |
enumerateDevices() |
Liste les micros, caméras et périphériques disponibles. | Les libellés utiles apparaissent souvent après accord de permission, donc il faut penser l’UX dans cet ordre. |
Dans mes projets, je sépare presque toujours la prévisualisation locale du flux distant. Le premier sert à rassurer l’utilisateur et à vérifier le micro ou la caméra avant l’appel ; le second dépend de la connexion distante et doit donc être conçu pour échouer proprement. C’est un détail d’interface, mais il change beaucoup la perception de fiabilité.
Je fais aussi attention à la lecture automatique des flux distants : selon le navigateur et le contexte, il faut parfois un geste utilisateur ou un média d’abord muet. Si on néglige ce point, on croit à tort que le problème vient du réseau alors qu’il vient du navigateur.
Ces briques posent la base. Reste maintenant à savoir quel modèle adopter selon le type de produit que vous construisez.
Appel un-à-un, conférence ou partage d’écran, ce qui change vraiment
La topologie a un impact direct sur le front-end. Un appel à deux est le cas le plus simple : chaque pair échange un flux avec l’autre, l’interface reste lisible et la gestion des pistes est modérée. Dès qu’on passe à un groupe, la complexité grimpe vite.
En configuration “mesh”, chaque participant envoie son flux à tous les autres. Cela reste acceptable pour une petite réunion, mais l’upload de chaque client se multiplie et l’interface doit gérer plusieurs vidéos simultanées. Je le garde pour les petits effectifs seulement, car au-delà on paie le coût réseau côté utilisateur.
Pour une vraie conférence, une architecture de type SFU devient souvent plus pertinente. Le front-end reçoit alors plusieurs pistes depuis un serveur relais spécialisé, ce qui simplifie le débit sortant côté client, mais impose une UI plus solide pour afficher, couper, mettre en avant ou réorganiser les intervenants. Le problème principal n’est plus seulement le transport, c’est la lisibilité de l’expérience.
Le partage d’écran suit une autre logique. Il vient souvent s’ajouter à une conversation déjà existante, avec une piste vidéo ou un canal de contrôle en plus. Je conseille de traiter ce flux comme un état à part entière dans l’interface, pas comme un simple bouton secondaire. Sinon, on finit avec des comportements confus quand l’utilisateur démarre, remplace ou arrête son partage.
Cette question de topologie mène naturellement à un autre arbitrage fréquent : faut-il choisir WebRTC, WebSocket ou SSE pour le besoin réel du produit ?
Quand je choisis WebRTC plutôt que WebSocket ou SSE
Je ne remplace jamais un besoin simple par une pile plus lourde. Le bon choix dépend du type de données, du sens de circulation et de la latence attendue. Voici le tri que je fais le plus souvent.
| Besoin | Choix le plus adapté | Pourquoi |
|---|---|---|
| Appel audio ou vidéo en direct | WebRTC | Le navigateur gère nativement le média, la négociation et les échanges pair à pair. |
| Chat texte, présence, notifications bidirectionnelles | WebSocket | Plus simple à maintenir, très lisible côté serveur comme côté client. |
| Flux unidirectionnel du serveur vers le client | SSE | Pratique pour des événements simples sans bidirectionnalité permanente. |
| Synchronisation légère entre deux pairs | WebRTC avec RTCDataChannel
|
Utile si vous voulez rester pair à pair et garder une latence faible. |
En clair, je ne conseille pas WebRTC pour un chat texte classique si la vidéo n’est pas au cœur du produit. À l’inverse, je ne conseille pas WebSocket pour une visioconférence en espérant obtenir la même expérience qu’avec un transport média dédié. Le bon outil dépend moins de la mode que du comportement attendu par l’utilisateur.
Une fois ce choix posé, les vrais problèmes apparaissent souvent ailleurs : permissions, réseau, compatibilité et maintenance. C’est là que beaucoup de prototypes se dégradent.
Les erreurs qui font dérailler un projet
La première erreur, c’est de sous-estimer les permissions. Si l’utilisateur refuse le micro ou la caméra, votre interface doit le montrer immédiatement et proposer une sortie claire. Un simple message d’échec technique ne suffit pas ; il faut expliquer quoi faire ensuite.
La deuxième erreur, c’est de compter sur une connexion directe sans prévoir le relais TURN. Le jour où un client est derrière un pare-feu strict, la démonstration qui marchait en Wi-Fi domestique devient inutilisable. Je considère donc TURN comme une assurance de compatibilité, pas comme une option de luxe.
La troisième erreur, plus discrète, consiste à ignorer la renégociation. Dès que l’utilisateur active ou désactive une caméra, partage un écran ou change de périphérique, la session peut devoir évoluer. Si vous ne gérez pas negotiationneeded et les transitions d’état, vous allez accumuler des bugs rares mais pénibles.
Je vois aussi souvent des interfaces qui oublient de libérer les pistes locales, de fermer la connexion lors d’un changement de route ou de nettoyer un composant React en démontant la vue. Résultat : caméra encore allumée, sessions fantômes, consommation CPU inutile. Ce n’est pas spectaculaire, mais c’est le genre de défaut qui use les utilisateurs.
Enfin, il faut tester avec de mauvais réseaux, pas seulement avec une fibre stable. Entre la 4G fluctuante, les limitations mobiles et les politiques d’autoplay, une application peut sembler parfaite en interne et moyenne chez les vrais utilisateurs. Ce décalage-là est presque toujours plus coûteux que le choix initial de la pile technique.
Pour éviter ce piège, je termine toujours par une vérification très concrète avant la mise en production.
Ce que je verrouille avant de livrer une expérience temps réel
Avant de considérer une session temps réel comme prête, je vérifie quelques points simples mais non négociables :
- Le site tourne en HTTPS et les permissions sont demandées au bon moment.
- Le signalement est idempotent, avec gestion des reprises et des offres en doublon.
- Les états de connexion sont visibles dans l’UI, pas seulement dans la console.
- Le plan de secours existe : audio seul, reconnexion, changement de périphérique ou bascule TURN.
- Les composants libèrent correctement les pistes, les objets de connexion et les écouteurs d’événements.
- Le produit est testé sur mobile, desktop et au moins un environnement réseau plus contraignant qu’un bureau standard.
Quand ces bases sont en place, la technologie cesse d’être un sujet d’atelier et devient une vraie capacité produit. C’est là que WebRTC prend tout son sens : non pas comme une démonstration technique, mais comme une expérience fluide, lisible et robuste dans le navigateur.
Si je devais résumer l’approche en une phrase, je dirais ceci : la réussite ne dépend pas seulement de la connexion pair à pair, mais de tout ce que l’interface fait avant, pendant et après cette connexion. C’est précisément pour cela qu’un bon frontend change complètement la valeur perçue d’un produit temps réel.