
Dans un environnement DevOps, la vraie question n’est pas seulement de déployer vite, mais de savoir ce qui survit quand un conteneur s’arrête, qu’un nœud redémarre ou qu’une coupure de courant survient. Le terme persistent storage recouvre justement le stockage qui garde les données au-delà du cycle de vie de l’instance, ce qui devient essentiel dès qu’une application manipule des fichiers, des sessions, des uploads ou une base de données. Je vais t’expliquer où se situe la frontière avec le stockage éphémère, quelles options marchent vraiment en production et comment éviter les pièges les plus coûteux.
Les points essentiels à garder en tête avant de choisir un stockage persistant
- Un conteneur sans volume dédié est, par défaut, éphémère: redémarrage rime souvent avec perte de données locales.
- En Docker, les volumes sont faits pour la persistance; les bind mounts servent surtout à partager un chemin du host.
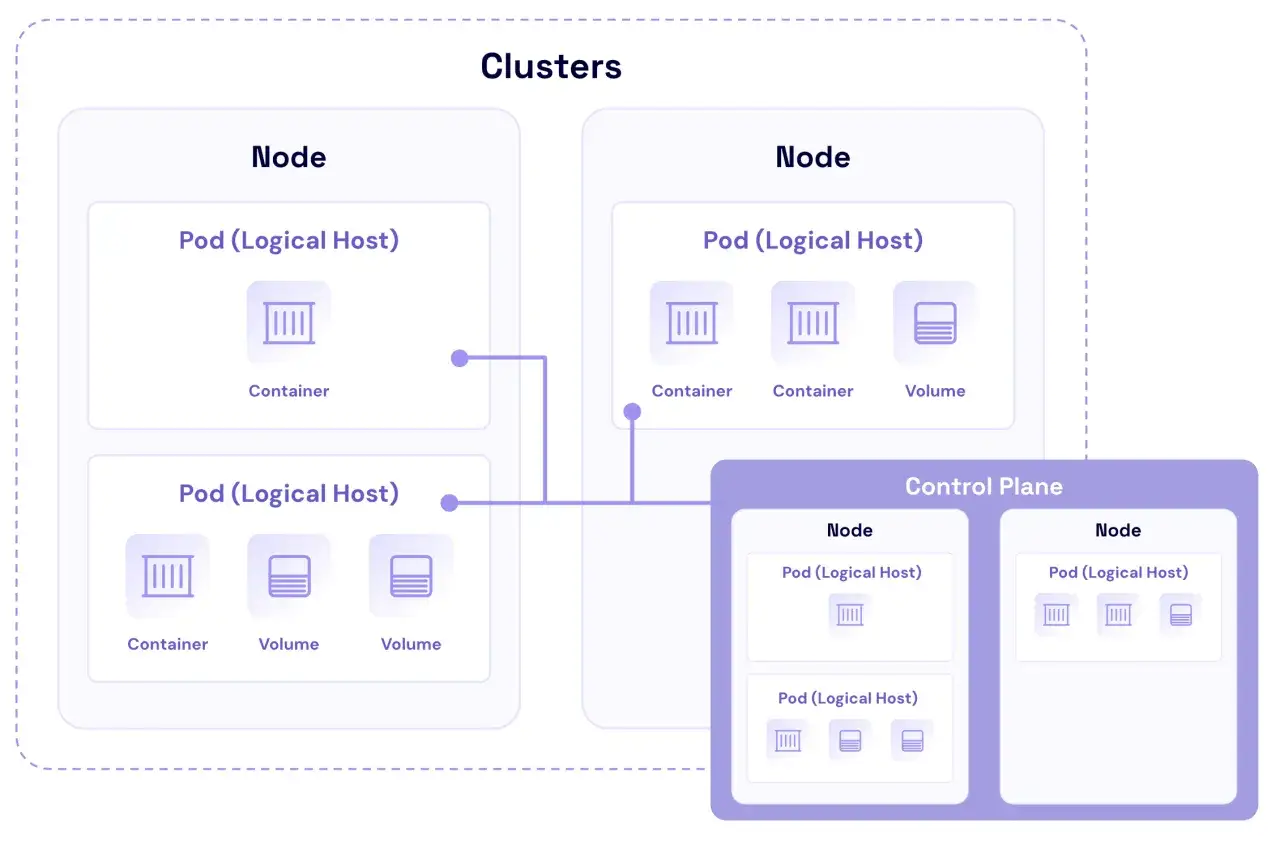
- En Kubernetes, PVC, PV et StorageClass séparent la demande de stockage, la ressource réelle et sa politique de provisioning.
- Pour une base de données, je privilégie presque toujours une architecture stateful avec sauvegardes et stratégie de reprise, pas un simple montage de répertoire.
- Le bon choix dépend surtout de la latence, du besoin de portabilité, du coût et du niveau de reprise après incident attendu.
Pourquoi le stockage éphémère ne suffit pas
Dans beaucoup de stacks, le système de fichiers d’un conteneur est par défaut jetable. C’est très bien pour un service stateless, un cache ou un job temporaire; c’est catastrophique pour des données métier. Dès que le conteneur est remplacé, mis à jour ou reprogrammé sur un autre nœud, tout ce qui n’a pas été externalisé disparaît avec lui.
Je vois encore trop souvent des équipes stocker des uploads, des fichiers de traitement ou des artefacts applicatifs directement dans le conteneur parce que “ça marche en local”. Le problème n’est pas théorique: au premier déploiement, au premier scale-out ou au premier incident d’infrastructure, le modèle casse. Une application tolère très bien de perdre un cache; elle ne tolère pas de perdre une commande validée, une image envoyée par un client ou l’état d’une file de traitement. La bonne règle est simple: si la donnée doit survivre à un redémarrage, elle ne doit pas vivre dans le conteneur.
C’est à partir de là qu’on peut parler sérieusement de stockage persistant et de l’architecture qui va avec.
Ce que recouvre vraiment le stockage persistant
Le stockage persistant conserve les données quand l’alimentation coupe, quand le processus s’arrête ou quand le conteneur est recréé. En pratique, cela peut être un disque local, un volume Docker, un PV Kubernetes, un partage réseau ou un objet stocké hors de la machine qui exécute l’application. Le point commun n’est pas la technologie: c’est l’indépendance vis-à-vis du cycle de vie du conteneur.
Ce n’est pas une sauvegarde. Une donnée persistante peut quand même être supprimée, corrompue ou chiffrée par erreur. La persistance dit seulement où la donnée vit au quotidien; la sauvegarde dit comment je la récupère après un incident. Dans un plan DevOps sérieux, les deux vont ensemble.
Ce n’est pas forcément du stockage distant
Un disque local peut être persistant s’il est monté correctement et si l’orchestration sait ce qu’elle fait. En revanche, il reste lié à la machine qui le porte. C’est souvent acceptable pour des besoins de faible latence ou des workloads prévisibles, mais beaucoup moins pour des services qui doivent bouger facilement d’un nœud à l’autre.
Lire aussi : Copie SSH - scp, rsync, sftp : Lequel choisir et pourquoi ?
Ce n’est pas la même chose qu’un répertoire partagé
Partager un dossier du host avec un conteneur peut dépanner en développement, mais ce n’est pas un modèle de persistance robuste par défaut. On y gagne en visibilité immédiate, on y perd en isolation, en portabilité et parfois en sécurité. C’est utile pour le code source ou certains fichiers de configuration; beaucoup moins pour une base de données ou un flux critique.
Une fois cette distinction claire, on peut comparer les options disponibles sans mélanger les usages.
Les options qui fonctionnent le mieux en DevOps
Quand je choisis une solution, je ne regarde pas seulement la capacité de stockage. Je regarde surtout la mobilité des workloads, le nombre de consommateurs, la facilité de reprise et le niveau de contrôle que l’équipe veut garder sur l’infrastructure.
| Solution | Quand je la choisis | Atout principal | Limite à connaître |
|---|---|---|---|
| Volume Docker | Application mono-hôte, prototype ou service simple | Persistance simple et intégrée au moteur Docker | Moins adapté si l’instance doit changer souvent de machine |
| Bind mount | Développement, tests locaux, partage de fichiers avec le host | Accès direct au système de fichiers du host | Couplage fort à la machine et risque accru d’erreur ou de sécurité |
| PV/PVC Kubernetes | Service orchestré qui doit survivre aux remplacements de pods | Séparation claire entre la demande de stockage et la ressource réelle | Configuration plus exigeante, surtout sur les classes de stockage et les droits |
| Local Persistent Volume | Cas sensibles à la latence, données proches du nœud | Bonnes performances brutes | Le volume reste lié à un nœud précis |
| Stockage objet | Fichiers, médias, exports, sauvegardes, archives | Très bon pour la durabilité et l’échelle | Ce n’est pas un système de fichiers POSIX classique |
La différence pratique est énorme: un volume Docker ou un PVC protège un état applicatif, alors qu’un stockage objet sert mieux les blobs et les artefacts. Si je dois choisir vite, je me demande d’abord si l’application écrit comme une base, comme un service de fichiers ou comme un producteur d’objets. C’est ce tri initial qui évite les architectures bancales.
Dans Kubernetes, je garde aussi un œil sur le mode d’accès. RWO convient souvent à une base qui n’a qu’un seul writer, tandis que RWX est utile quand plusieurs pods doivent voir le même contenu. Si le mode d’accès ne colle pas au besoin réel, aucune magie d’orchestration ne compensera l’erreur.
À partir de là, la vraie question devient: comment transformer ce choix en déploiement propre et testable?
Comment je choisis la bonne stratégie selon l’application
Je pars toujours du comportement des données, pas de la mode du moment. Une base transactionnelle, un CMS avec uploads, un service de traitement batch et un cache applicatif ne demandent pas le même niveau de persistance ni le même coût d’exploitation.
- Base de données : volume dédié, sauvegarde régulière, restauration testée et, si nécessaire, réplication. Je ne fais jamais confiance au seul disque local sans plan de reprise.
- Fichiers envoyés par les utilisateurs : je préfère souvent l’objet stocké hors du pod, avec métadonnées dans la base. C’est plus simple à faire évoluer et à sécuriser.
- Uploads temporaires ou caches : je reste sur du jetable si la perte est acceptable. Ici, la persistance ajoute parfois de la complexité sans bénéfice réel.
- Logs applicatifs : je les centralise plutôt que de les laisser s’accumuler sur le disque du conteneur. Les logs locaux sont utiles pour le dépannage, pas comme stratégie de rétention.
- Artefacts de build : selon le cas, un volume persistant ou un stockage d’artefacts dédié fonctionne mieux qu’un répertoire du host exposé à tout le monde.
Le point de rupture arrive généralement quand plusieurs pods doivent écrire au même endroit. Là, il faut arbitrer entre simplicité, cohérence et performance. En pratique, plus le besoin de partage augmente, plus je préfère externaliser les données ou passer par un service conçu pour cela plutôt que de bricoler un répertoire commun.
Une fois le scénario clarifié, je peux mettre en place la persistance de façon propre au lieu de la greffer après coup.
Mettre en place une persistance fiable dans un cluster
Dans Kubernetes, je sépare toujours la demande de stockage, la ressource et le pod. Le couple PVC/PV me permet de garder cette séparation nette, et StorageClass décrit la qualité de stockage attendue. C’est cette couche d’abstraction qui évite de figer l’application sur un disque précis.
- Je classe la donnée : critique, reconstructible, cache, archive.
- Je choisis le backend : bloc, fichier ou objet selon le besoin.
-
Je définis la politique : taille,
reclaimPolicy, expansion éventuelle, et si le volume doit être créé automatiquement. -
Je branche le volume au pod via un
PVCou, pour un workload stateful, via unStatefulSet. - Je teste la panne : arrêt du pod, remplacement du nœud, puis restauration depuis une sauvegarde ou un snapshot.
Je fais aussi attention aux permissions. Un volume monté avec le mauvais UID/GID, ou sans fsGroup correctement réglé, finit souvent en incident de mise en production alors que le problème n’est pas le stockage lui-même, mais l’accès au stockage. Sur les données sensibles, j’ajoute chiffrement au repos, contrôle d’accès strict et séparation claire entre secrets et fichiers persistés.
Le détail qui change beaucoup de choses, c’est le reclaimPolicy: avec Retain, je garde le volume même si le PVC disparaît; avec Delete, je simplifie le nettoyage mais je prends plus de risques si la suppression est accidentelle. Ce choix mérite une vraie décision d’équipe, pas un paramètre laissé par défaut.
Les erreurs qui font perdre des données
La plupart des pertes de données que je vois en pratique ne viennent pas d’un bug exotique. Elles viennent d’un mauvais modèle mental: on croit avoir “sauvegardé” alors qu’on a juste écrit dans un endroit temporaire, ou on a branché un volume sans vérifier son comportement réel au redéploiement.
- Confondre persistance et sauvegarde : un volume plein ou corrompu reste un problème, même s’il est persistant.
- Utiliser le répertoire du conteneur comme source de vérité : au redémarrage, il disparaît souvent.
- Monter un chemin du host sans standardisation : cela marche sur une machine et casse sur une autre.
- Ignorer les permissions : le volume existe, mais l’application ne peut pas écrire dedans.
- Choisir un volume local pour un service qui doit migrer : la panne d’un nœud devient alors une panne de données.
- Ne jamais tester la restauration : c’est l’erreur la plus coûteuse, parce qu’elle reste invisible jusqu’au jour où elle compte.
J’ajoute volontiers un test simple à ma checklist: supprimer le pod, redémarrer le nœud ou restaurer un volume vide et vérifier si l’application repart avec les mêmes données. Si ce test échoue, je considère que la persistance n’est pas prête, même si tout “semble” fonctionner en production.
Cette discipline de vérification amène naturellement la dernière question: qu’est-ce que je valide juste avant de laisser le service tourner seul?
Ce que je valide avant de laisser tourner la charge réelle
Avant le passage en production, je valide toujours trois choses: la donnée survit à un redémarrage simple, la reprise après incident est documentée, et la restauration marche vraiment avec un jeu de données réaliste. Je préfère un test de 10 minutes bien fait à une confiance abstraite construite sur un environnement de dev qui n’a jamais subi de panne.
- Un redémarrage du pod pour vérifier que les fichiers reviennent au bon endroit.
- Une bascule de nœud ou un remplacement d’instance pour confirmer que la solution supporte l’orchestration réelle.
- Une restauration complète pour savoir combien de temps il faut et quelles données reviennent.
- Un contrôle de capacité pour éviter qu’un volume à 90 % déclenche l’incident que personne n’avait anticipé.
Si je devais résumer ma pratique en une phrase, je dirais ceci: le bon stockage persistant n’est pas celui qui existe seulement dans la console d’administration, mais celui qui continue de fonctionner quand le déploiement bouge, que l’infrastructure se réorganise et que l’équipe a vraiment besoin des données. C’est là que la différence entre un système “qui tourne” et un système exploitable devient visible.