
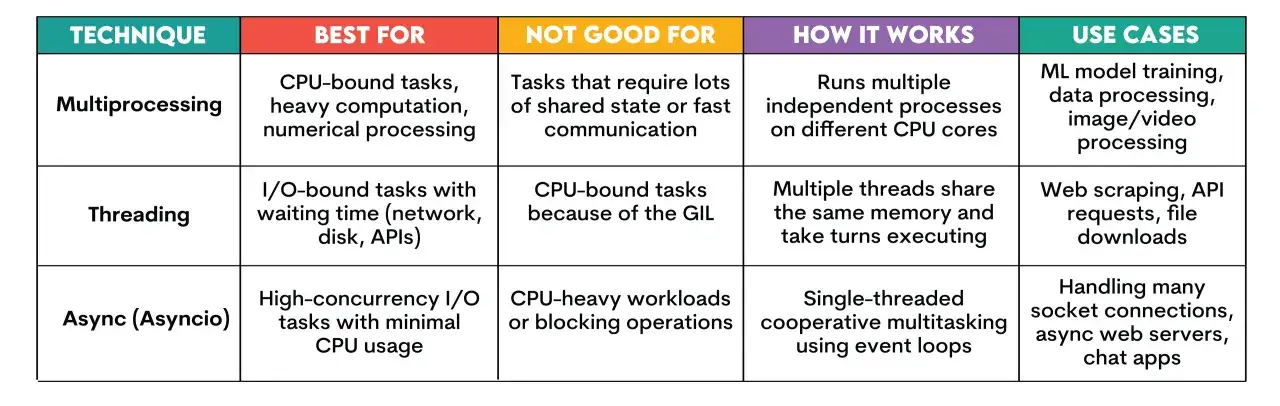
Quand une tâche Python monopolise un cœur, le bon réflexe n’est pas toujours d’ajouter des threads. Avec python multiprocessing, on répartit le travail sur plusieurs processus indépendants, ce qui change vraiment la donne pour les calculs lourds, les lots de données et certains traitements backend. Je vais aller droit aux points utiles: quand cette approche aide, comment choisir le bon mode de démarrage, quelle API privilégier, comment faire circuler les données sans ralentir le tout, et quels pièges je surveille en production.
Les points clés à retenir avant de lancer plusieurs processus
- Les processus servent surtout les tâches CPU-bound; pour l’I/O, les threads ou asyncio restent souvent plus simples.
- Le mode de démarrage change la compatibilité, le coût de lancement et la manière dont les objets sont transmis.
- Un pool de workers est efficace seulement si le coût du calcul compense le coût de coordination et de sérialisation.
- La communication entre processus passe presque toujours par la sérialisation, donc les gros objets doivent être traités avec prudence.
- En backend, je réserve cette approche aux jobs bornés plutôt qu’au chemin critique d’une requête.
Quand les processus apportent vraiment quelque chose
Les processus servent surtout quand le temps perdu n’est pas de l’attente, mais du calcul. Là où les threads partagent le même interpréteur et se heurtent au GIL pour l’exécution du bytecode Python, des processus séparés avancent réellement en parallèle sur plusieurs cœurs. Le GIL, ou Global Interpreter Lock, limite l’exécution simultanée du bytecode dans un même processus; c’est pour cela que je garde les processus pour les tâches intensives, pas pour les appels HTTP ou les requêtes base de données.
| Situation | Choix que je privilégie | Pourquoi |
|---|---|---|
| Calcul d’images, hashing, parsing massif, compression | Processus | Le travail est CPU-bound et peut vraiment profiter de plusieurs cœurs. |
| Appels réseau, accès base de données, lecture de fichiers simple | Threads ou asyncio | Le goulot est surtout l’attente, pas le calcul. |
| Traitement de lots, export de rapports, enrichissement de données | Hybride | Un pool de processus peut accélérer le calcul, tandis que le reste du pipeline reste léger. |
Je ne bascule donc pas vers plusieurs processus dès qu’un script ralentit. Si le problème vient surtout de l’I/O, le gain est souvent faible et la complexité monte vite. Avant de choisir une API, il faut d’ailleurs comprendre comment les processus démarrent et ce qu’ils héritent du parent.
Comprendre fork, spawn et forkserver
La documentation Python précise que, sur POSIX, le mode par défaut est désormais forkserver; sur macOS et Windows, c’est spawn. Ce détail change la manière dont les objets sont copiés, réimportés et nettoyés, donc je le vérifie toujours avant de déployer. En pratique, le choix du mode a un impact direct sur la vitesse de démarrage, la compatibilité avec les threads et la facilité de sérialisation des fonctions.
| Mode | Atout principal | Limite à garder en tête | Mon usage habituel |
|---|---|---|---|
fork |
Démarrage très rapide, état du parent copié presque tel quel. | Risque réel avec les programmes multithreadés; ce n’est plus le défaut. | Seulement si je maîtrise totalement l’environnement et que j’ai besoin de ce comportement précis. |
spawn |
Interpréteur neuf, comportement propre et portable. | Démarrage plus lent, fonctions et objets à rendre sérialisables. | Mon choix de sécurité par défaut, surtout quand le code doit tourner sur plusieurs systèmes. |
forkserver |
Bon compromis sur POSIX: plus robuste que fork, souvent plus rapide que spawn. |
Disponible sur POSIX uniquement; ajoute un serveur et un tracker de ressources. | Le mode que je teste en priorité sur Linux quand je veux un bon équilibre entre robustesse et performance. |
Sur POSIX, spawn et forkserver lancent aussi un resource tracker, utile pour nettoyer des ressources nommées comme les sémaphores ou la mémoire partagée si un worker s’arrête brutalement. Cette partie est facile à négliger, mais elle évite des fuites pénibles à diagnostiquer. Une fois le mode fixé, le vrai choix devient celui de l’API la plus lisible pour votre cas.
Choisir entre Process, Pool et ProcessPoolExecutor
Je vois souvent trois niveaux de réponse. Process suffit pour un ou quelques travaux longs avec une logique de cycle de vie très précise. Pool est pratique quand j’ai beaucoup de tâches homogènes à distribuer. ProcessPoolExecutor est agréable quand le code applicatif parle déjà en Future et que je veux une orchestration moderne sans trop de plomberie.
| API | Quand je l’utilise | Avantage principal | Limite |
|---|---|---|---|
Process |
Un job long, quelques travailleurs, contrôle manuel. | Contrôle total sur le démarrage, l’arrêt et l’assemblage. | Je dois écrire moi-même davantage d’orchestration. |
Pool |
Beaucoup de tâches similaires à paralléliser. |
map, imap, imap_unordered, chunksize: tout est pensé pour le batch. |
Moins naturel si toute mon architecture repose déjà sur des Future. |
ProcessPoolExecutor |
Code applicatif moderne, intégration avec concurrent.futures. |
API claire, submit et as_completed très lisibles. |
Un peu moins de contrôle bas niveau que Pool. |
Si votre code parle déjà en Future, ProcessPoolExecutor me paraît souvent plus lisible. Si vous avez besoin de réglages précis sur le débit ou sur les lots, Pool reste excellent. Le point clé n’est pas l’outil lui-même, mais la forme des fonctions envoyées aux workers.
Monter un pool de workers proprement
Le point qui évite la majorité des déceptions, c’est la structure de la tâche. Une fonction de worker doit être définie au niveau du module, recevoir des arguments simples si possible et éviter de capturer un état implicite. Je préfère aussi choisir le contexte explicitement, surtout quand le code doit rester portable entre Linux, macOS et Windows.
import multiprocessing as mp
from hashlib import sha256
def digest(blob: bytes) -> str:
return sha256(blob).hexdigest()
def main() -> None:
payloads = [b"alpha", b"beta", b"gamma", b"delta"]
ctx = mp.get_context("spawn") # portable et explicite
with ctx.Pool(processes=4) as pool:
for value in pool.imap_unordered(digest, payloads, chunksize=2):
print(value)
if __name__ == "__main__":
main()J’utilise imap_unordered quand l’ordre final n’a pas d’importance, parce qu’il laisse remonter les résultats au fur et à mesure. Pour un rapport, un export ou un traitement batch, ce comportement donne souvent une sensation de fluidité très concrète. Si l’ordre compte, je reviens à map, mais je perds ce streaming des résultats.
Quand les tâches sont petites et très nombreuses, chunksize devient important: il amortit le coût de coordination entre processus. Et si chaque worker doit charger un modèle, un cache ou une ressource lourde une seule fois, j’utilise un initializer pour éviter de répéter ce travail à chaque tâche. C’est souvent là que le gain réel apparaît, pas dans la simple création du pool.
Faire circuler les données entre processus sans casse
Dès qu’un objet traverse la frontière d’un processus, Python doit le sérialiser. Le pickling est cette sérialisation native qui transforme un objet en octets pour le transporter entre processus; c’est pratique, mais chaque aller-retour a un coût. En pratique, je limite les objets qui passent par le canal interprocessus et je privilégie les identifiants, les offsets ou les petits messages quand c’est possible.
| Mécanisme | À quoi il sert | Force principale | Limite |
|---|---|---|---|
Queue |
Échanger des objets sérialisés entre producteurs et consommateurs. | Simple, robuste, très utile pour des pipelines de tâches. | Le passage d’objets volumineux finit par coûter cher. |
Pipe |
Relier deux processus avec un canal direct. | Très léger quand le schéma est strictement point à point. | Moins adapté aux fan-outs ou aux architectures plus complexes. |
SharedMemory |
Partager directement des buffers, tableaux ou gros blocs binaires. | Évite les copies répétées quand la donnée est volumineuse. | Demande une gestion propre de close() et unlink(). |
Manager |
Exposer des structures de type dictionnaire ou liste à plusieurs processus. | Pratique pour coordonner sans tout réécrire. | Les proxies sont plus lents; je l’évite dans les boucles chaudes. |
La documentation Python rappelle que SharedMemory est fait pour être accessible par un ou plusieurs processus sur une machine multicœur. C’est intéressant pour des images, des matrices ou de gros buffers binaires, surtout quand la copie coûterait plus cher que le calcul lui-même. Cette partie est souvent négligée, alors qu’elle décide si le parallélisme accélère vraiment ou s’il ne fait que déplacer le coût ailleurs.
Les erreurs qui reviennent tout le temps
Les soucis les plus fréquents sont rarement spectaculaires; ils sont surtout répétitifs. Je les vois revenir dans les scripts d’automatisation comme dans les services backend, souvent parce que le passage au multi-processus a été tenté trop tôt ou sans contrainte claire.
-
Oublier le garde
if __name__ == "__main__": surspawn, le module est réimporté et le code de niveau supérieur peut se relancer. - Passer des lambdas, fonctions imbriquées ou objets non sérialisables: le worker doit pouvoir reconstruire la cible proprement.
- Partager une connexion DB ou un client HTTP créé dans le parent: chaque processus doit gérer ses propres ressources.
- Lancer un pool par requête: le coût de démarrage finit par manger le gain du parallélisme.
- Créer trop de workers: sur une VM de 8 Go, quelques processus lourds suffisent déjà à faire grimper la pression mémoire.
-
Oublier la fermeture propre des ressources: pour la mémoire partagée, il faut penser à
close()puisunlink(). - Ignorer les exceptions remontées par les workers: un lot silencieusement incomplet prend beaucoup plus de temps à diagnostiquer qu’un échec net.
Quand ces pièges sont écartés, la question devient moins technique que stratégique: où placer les processus dans la chaîne de traitement, et à quel moment leur coût reste acceptable?
Le réglage que je garde pour un backend qui doit rester stable
Dans un backend, je réserve plutôt python multiprocessing aux tâches bornées: génération de PDF, transformations d’images, recalcul de métriques, enrichissement de lots ou post-traitement d’événements. Je l’aime moins dans le chemin critique d’une requête, parce qu’un processus lancé au mauvais endroit ajoute de la latence et peut doubler la consommation mémoire si l’application tourne déjà avec plusieurs workers web.
Je suis aussi attentif à l’environnement d’exécution. Dans un conteneur limité à 2 cœurs, un pool de 8 processus n’achètera rien; dans une VM de 8 Go, un worker qui charge un modèle ou un cache lourd peut faire monter la pression mémoire très vite. Je pars donc avec un nombre de processus égal à la capacité réellement disponible, puis je mesure sur de vraies charges, pas sur une intuition.
Si je devais résumer la règle pratique, je dirais qu’on utilise les processus pour absorber du calcul, pas pour masquer une architecture mal découpée. Dès que le besoin principal devient l’I/O, l’échange d’état ou la simplicité opérationnelle, je reviens à un autre modèle; sinon, je garde les workers courts, les objets petits et le contrôle explicite du démarrage.