 - Quand l'utiliser et ses meilleures alternatives")
Quand on nettoie des données d’API, des logs ou une liste d’utilisateurs, on a souvent besoin d’éliminer le superflu sans alourdir le code. La fonction `filter()` de Python sert précisément à conserver les éléments qui satisfont une condition, avec une syntaxe courte et un comportement paresseux qui peut économiser de la mémoire. Je vais montrer comment elle fonctionne, quels cas elle résout bien, et pourquoi une compréhension de liste reste souvent plus lisible.
L’essentiel à retenir sur filter() en Python
-
`filter()` renvoie un itérateur, pas une liste: il faut souvent l’envelopper dans
list()pour l’afficher ou le réutiliser. - Le deuxième argument peut être n’importe quel itérable: liste, tuple, chaîne, générateur ou autre flux de données.
- La fonction de test agit comme un prédicat: si elle renvoie une valeur vraie, l’élément est conservé.
- Avec
None, Python garde seulement les valeurs truthy et supprime les valeurs falsy. - Pour beaucoup de cas simples, une compréhension de liste reste plus lisible qu’un filtre explicite.
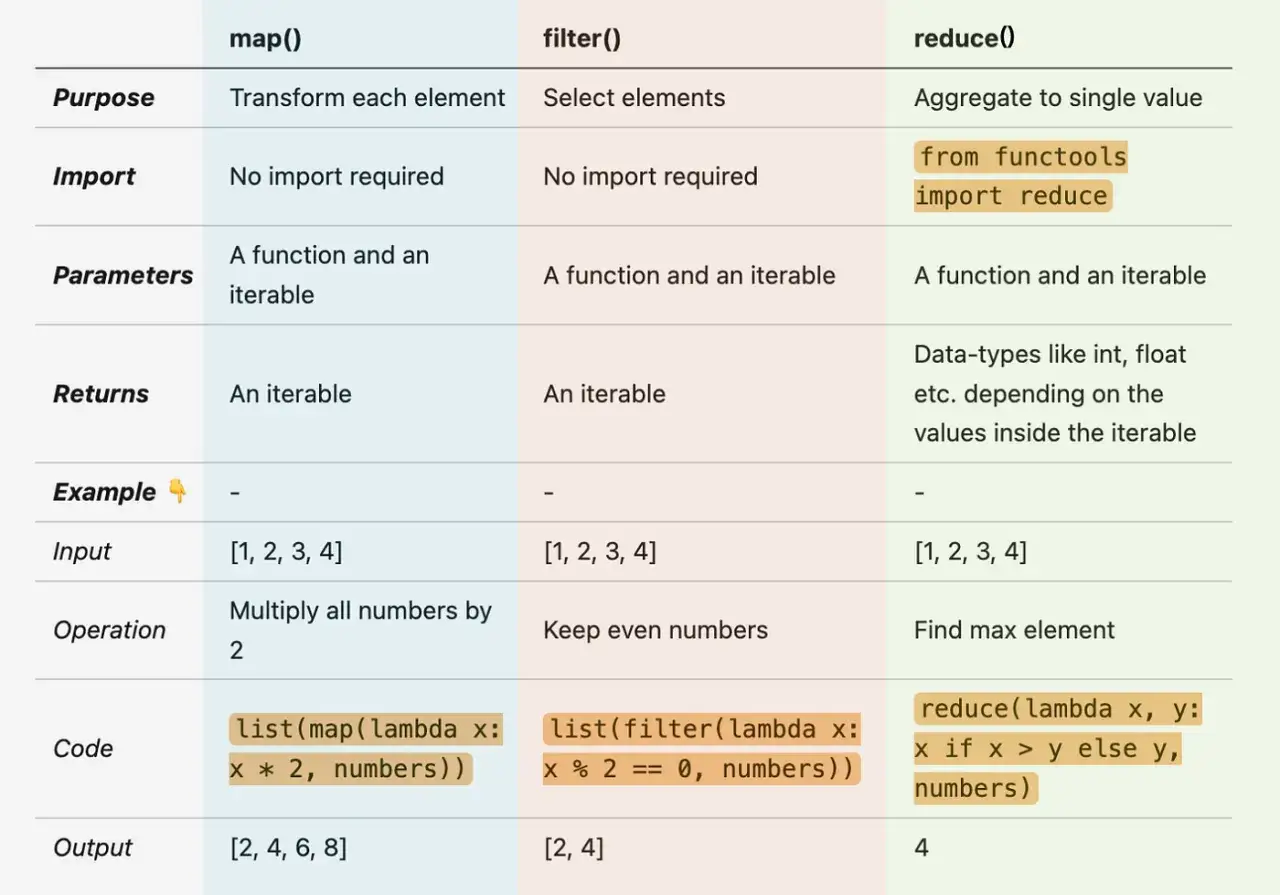
Comment filter() parcourt vos données
Le principe est simple: on donne à filter() un prédicat, c’est-à-dire une fonction d’un seul argument qui renvoie une valeur interprétable comme vraie ou fausse, puis un itérable à parcourir. Python teste chaque élément un par un et ne garde que ceux qui passent la condition. En pratique, c’est proche d’un WHERE en SQL, sauf qu’on reste dans le monde des itérateurs Python.
Le point clé, c’est que filter() ne construit pas immédiatement une nouvelle liste. Il renvoie un itérateur, donc le filtrage est évalué au moment où l’on consomme le résultat. C’est utile pour traiter des volumes importants sans créer d’intermédiaire inutile, surtout dans un backend où l’on enchaîne plusieurs étapes sur les mêmes données.
nombres = [-3, -1, 0, 2, 5, 8]
positifs = filter(lambda x: x > 0, nombres)
print(positifs) #
print(list(positifs)) # [2, 5, 8]
Il faut aussi retenir qu’un itérateur se consomme. Si vous parcourez positifs une seconde fois, il sera vide. C’est souvent la première surprise quand on débute avec le filtrage paresseux.
La syntaxe à connaître et le cas spécial de None
La signature est courte: filter(function, iterable). La première partie est le prédicat, la seconde est la source des données. Cela fonctionne avec une liste, un tuple, une chaîne, un générateur ou tout autre objet itérable. Dès que l’objet sait être parcouru, il peut être filtré.
def est_pair(n):
return n % 2 == 0
resultat = list(filter(est_pair, [1, 2, 3, 4, 5, 6]))
print(resultat) # [2, 4, 6]
Le cas None est un raccourci très pratique: Python supprime alors les éléments falsy, c’est-à-dire les valeurs qui se comportent comme False dans un test logique. On enlève ainsi rapidement 0, False, None, "" et les conteneurs vides.
valeurs = [0, 1, "", "Python", None, [], [1]]
propres = list(filter(None, valeurs))
print(propres) # [1, 'Python', [1]]
Attention à un détail souvent mal compris: une chaîne contenant uniquement des espaces reste vraie. Si vous voulez éliminer les lignes vides et les lignes composées seulement d’espaces, il faut tester la version nettoyée de la chaîne.
lignes = [" ", "token", "\t", "header"]
non_vides = list(filter(str.strip, lignes))
print(non_vides) # ['token', 'header']
Dans ce cas, str.strip retire les espaces; si le résultat est vide, l’élément est écarté. C’est élégant, mais un prédicat nommé reste souvent plus explicite dans du code métier.
Des cas concrets qui reviennent souvent dans un projet backend
Dans un projet web, je vois surtout filter() utilisé pour nettoyer des listes avant sérialisation, isoler des enregistrements métier valides, ou extraire des événements utiles depuis un flux brut. Voici les cas qui reviennent le plus souvent, et pourquoi ils sont intéressants.
Garder seulement les nombres utiles
transactions = [120, -15, 0, 89, -3, 44]
def est_positive(montant):
return montant > 0
montants_valides = list(filter(est_positive, transactions))
print(montants_valides) # [120, 89, 44]
Ce type de filtre est banal, mais il est précieux dès qu’on prépare des totaux, des tableaux de bord ou des règles d’agrégation. Une valeur négative ou nulle peut avoir un sens métier, donc je ne la supprime pas automatiquement sans vérifier la règle fonctionnelle.
Nettoyer des chaînes avant affichage ou traitement
mots = ["api", "", "python", " ", "backend"]
propres = list(filter(str.strip, mots))
print(propres) # ['api', 'python', 'backend']
Ici, le filtre sert à préparer des données textuelles avant un rendu, une recherche ou une validation. C’est utile pour les formulaires, les tags, les commentaires ou les paramètres de requête qui arrivent parfois partiellement vides.
Conserver des objets métier selon une règle claire
users = [
{"id": 1, "active": True, "role": "admin"},
{"id": 2, "active": False, "role": "editor"},
{"id": 3, "active": True, "role": "viewer"},
]
def est_actif(user):
return user["active"]
actifs = list(filter(est_actif, users))
print(actifs)
Quand la règle est réutilisable, un prédicat nommé améliore nettement la lisibilité. Je préfère cette forme à une lambda opaque dès qu’une condition métier doit être comprise par quelqu’un d’autre dans l’équipe.
Lire aussi : SQLite Python - Le guide complet pour des bases solides
Filtrer des logs ou des événements de pipeline
events = [
{"level": "info", "message": "cache warm"},
{"level": "error", "message": "db timeout"},
{"level": "warning", "message": "retry"},
]
def est_erreur(event):
return event["level"] == "error"
erreurs = list(filter(est_erreur, events))
Ce cas est intéressant parce qu’il montre bien l’usage “pipeline”: on extrait d’abord ce qui compte, puis on formate, compte ou envoie ailleurs. C’est une façon propre de séparer la sélection des données du reste du traitement.
Pourquoi je compare presque toujours avec une compréhension de liste
Dans beaucoup de cas, filter() et une compréhension de liste résolvent le même problème. La vraie question n’est pas “lequel est plus Python”, mais “lequel reste le plus lisible pour le prochain humain qui lira le code”. Quand la logique devient légèrement plus riche, la compréhension de liste gagne souvent.
| Solution | Atout principal | Limite fréquente | Je la choisis quand |
|---|---|---|---|
filter() |
Très lisible avec un prédicat nommé et un comportement paresseux | Peut devenir opaque avec une lambda complexe |
La règle de sélection existe déjà et je veux enchaîner un pipeline |
| Compréhension de liste | Clair, compact, très naturel pour filtrer et lire la logique d’un coup d’œil | Crée la liste immédiatement | La condition est simple ou je combine sélection et transformation |
| Expression génératrice | Laziness et faible empreinte mémoire | Moins directe à lire si l’expression est longue | Je veux traiter un flux sans tout matérialiser |
Boucle for
|
Maximalement explicite pour des règles complexes | Plus verbeux | Il y a des effets de bord, plusieurs branches ou beaucoup de contexte métier |
Mon réflexe est assez simple: si je peux écrire la sélection en une ligne claire, je le fais; si je dois expliquer la règle, je passe à une fonction nommée; si je dois filtrer et transformer dans la foulée, la compréhension de liste devient souvent plus élégante. La performance brute n’est généralement pas le vrai critère ici: c’est surtout la maintenabilité qui compte.
Les pièges qui reviennent le plus souvent
La plupart des erreurs avec le filtrage ne sont pas techniques, elles sont conceptuelles. On pense manipuler une liste, alors qu’on manipule un itérateur; on pense enlever du “vide”, alors qu’on supprime seulement les valeurs falsy; on pense clarifier le code, alors qu’on le rend moins lisible.
- Oublier que le résultat est paresseux: si vous avez besoin d’un accès multiple, convertissez en liste au bon moment.
-
Utiliser
filter()pour transformer: si vous modifiez les éléments en plus de les sélectionner, une compréhension de liste est souvent plus adaptée. -
Confondre chaînes vides et chaînes blanches:
filter(None, ...)ne supprime pas les chaînes composées d’espaces. -
Écrire une
lambdatrop dense: si la condition mérite une phrase, donnez-lui un nom. - Consommer l’itérateur deux fois: le premier parcours vide le résultat, le second ne renvoie plus rien.
it = filter(lambda x: x > 2, [1, 2, 3, 4])
print(list(it)) # [3, 4]
print(list(it)) # []
Ce dernier point mérite d’être gardé en tête dans un backend, car il peut provoquer des bugs discrets: tout semble fonctionner au premier traitement, puis un second composant récupère un résultat vide. Si plusieurs étapes doivent relire les mêmes données, je matérialise le résultat une fois, puis je le partage.
La règle simple que j’applique pour garder un code propre
Dans un code de production, je réserve filter() aux cas où la sélection est nette, réutilisable et naturellement paresseuse. Dès que la logique devient un peu plus narrative, je bascule vers une compréhension de liste ou une fonction nommée, parce que le gain de clarté est souvent supérieur au gain de concision.
-
Je garde
filter()quand un prédicat existe déjà et que je veux enchaîner un traitement sur un flux. - Je préfère une compréhension de liste quand la règle est courte et doit rester immédiatement lisible.
- Je matérialise en liste au moment où j’ai besoin de sérialiser, afficher ou réutiliser plusieurs fois le résultat.
- J’utilise un prédicat nommé dès que la condition a une vraie signification métier.
-
Je pense à l’alternative inverse avec
itertools.filterfalse()quand je cherche les éléments rejetés plutôt que conservés.
Dans un projet web, cette discipline évite beaucoup de flottement: je filtre près de la donnée brute, je garde le code lisible, et je ne convertis en structure concrète qu’au moment où c’est utile. C’est cette sobriété qui rend le filtrage Python vraiment agréable à maintenir.