
Le infinite scroll fonctionne bien quand l’objectif est la découverte rapide, pas quand l’utilisateur doit revenir souvent sur un point précis. Dans une interface frontend, ce choix agit sur tout le reste: repères visuels, navigation clavier, performance, URLs et même indexation. Je vais donc le traiter comme un vrai composant produit, avec ses cas d’usage, ses pièges et les réglages qui font la différence.
Les points à verrouiller avant de choisir ce pattern
- Le défilement continu sert surtout la découverte : il est efficace pour un flux, moins pour une recherche ciblée.
- Un déclenchement propre passe par `IntersectionObserver`, pas par un écouteur `scroll` qui tourne en permanence.
- La stabilité visuelle compte autant que le chargement : si les cartes poussent le contenu sans réserve d’espace, le CLS grimpe vite.
- L’accessibilité doit être prévue dès le départ : focus, annonces discrètes et alternative au chargement automatique.
- Le SEO n’est pas gratuit : pour un contenu indexable, il faut garder une version paginée ou des URLs stables.
- La virtualisation devient utile dès que la liste grossit vraiment, sinon le DOM finit par coûter plus cher que le fetch.
Quand le défilement continu est le bon choix
Je le garde pour les interfaces où l’utilisateur veut surtout explorer plutôt que chercher. Un fil d’actualité, une galerie d’inspiration, des recommandations produits ou des cartes de contenus courts s’y prêtent bien, parce que le geste reste simple: on lit, on scrolle, on continue. L’expérience paraît fluide parce qu’elle élimine la rupture mentale des pages successives.
En revanche, dès que l’utilisateur doit comparer, revenir en arrière ou atteindre un repère précis, le pattern perd de sa valeur. Le pied de page devient difficile à atteindre, les repères temporels ou sémantiques se diluent, et le sentiment de contrôle baisse. Pour décider proprement, je compare souvent les trois approches ci-dessous.
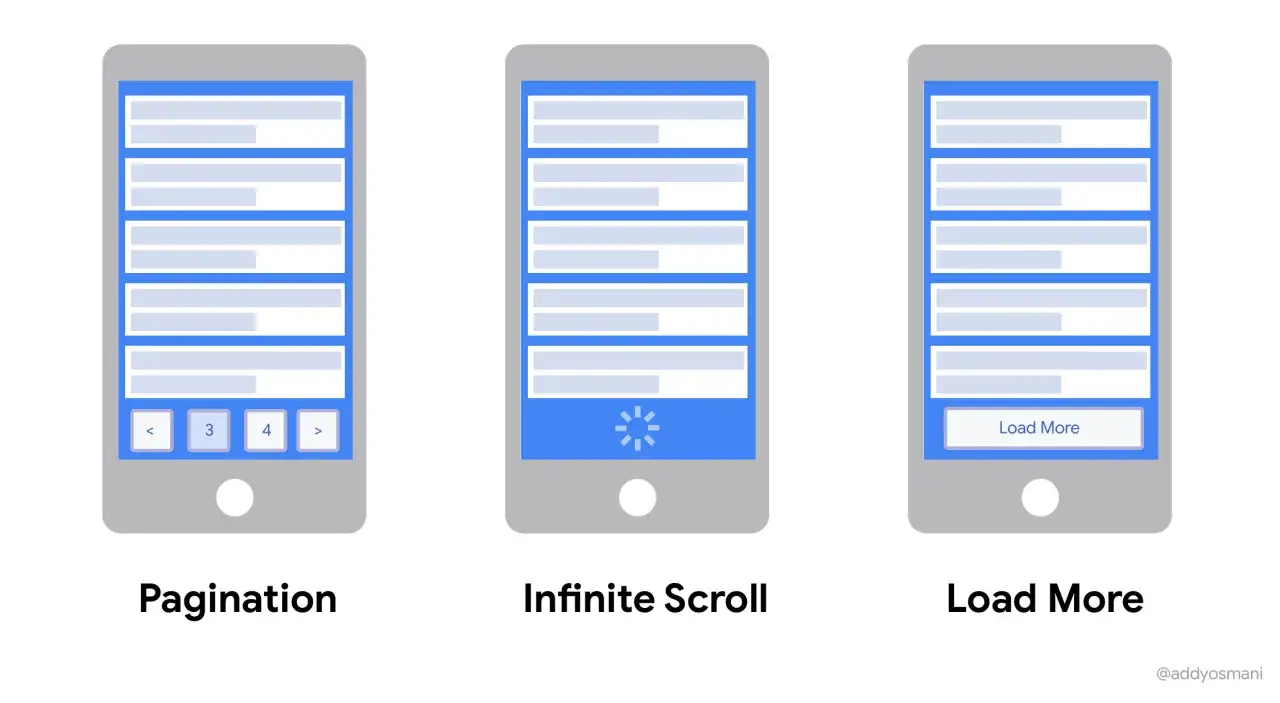
| Approche | Atout principal | Limite concrète | Je la choisis quand |
|---|---|---|---|
| Pagination | Repères clairs et URLs faciles à partager | Rupture de lecture à chaque page | Recherche précise, contenu éditorial, consultation structurée |
| Charger plus | Donne le contrôle à l’utilisateur | Ajoute un clic supplémentaire | Listes moyennes, catalogues, cas hybrides |
| Défilement continu | Flux très fluide et découverte rapide | Repères faibles, footer souvent repoussé | Feeds, inspiration, contenu à consommation rapide |
Mon filtre est simple: si le contenu doit être retrouvé, cité ou comparé, je m’éloigne du flux sans fin. Si l’objectif est seulement de faire circuler l’attention dans une liste cohérente, il peut être excellent. Une fois ce choix posé, la vraie difficulté devient technique: charger sans casser la mise en page ni la navigation.
Implémenter le chargement progressif sans bricolage côté client
La version propre commence presque toujours par la même idée: une API paginée ou à curseur, puis un sentinelle placé en bas de liste pour déclencher le chargement suivant. `IntersectionObserver` est l’outil le plus propre pour ça, parce qu’il observe la visibilité d’un élément sans monopoliser le thread principal comme le ferait un écouteur `scroll` mal réglé.
En pratique, je structure l’implémentation autour de quelques règles simples. Je charge le premier lot côté serveur ou au moins dans le HTML initial, je réserve une marge de préchargement avant que l’utilisateur atteigne réellement le bas, et je garde un état de pagination dans l’URL ou dans l’historique pour éviter l’effet « tout disparaît quand on revient en arrière ».
const observer = new IntersectionObserver(onReachEnd, {
rootMargin: "0px 0px 600px 0px"
});- Charge initiale visible : l’utilisateur doit voir du contenu immédiatement, pas un écran vide qui attend le second lot.
- Préchargement anticipé : une marge de 300 à 800 px suffit souvent à lancer la requête avant la fin réelle du viewport.
- Lots raisonnables : dans beaucoup d’interfaces, 20 à 40 éléments par requête restent lisibles et gérables.
- Gestion d’erreur explicite : si la requête échoue, je préfère un bouton “Réessayer” à un silence complet.
- Fin de liste visible : quand il n’y a plus rien à charger, il faut le dire clairement plutôt que laisser l’utilisateur dans le doute.
Cette base fonctionne bien, mais elle reste incomplète si elle oublie les gens qui ne naviguent pas au même rythme. C’est justement là que l’accessibilité devient décisive.
Garder la navigation lisible pour tous
Le problème classique, ce n’est pas seulement le chargement automatique. C’est le fait qu’un nouvel élément apparaît sans prévenir, que le focus se perd, ou que le lecteur d’écran n’a aucun indice sur ce qui vient d’arriver. Pour un flux d’articles, je préfère annoncer les ajouts dans une zone `aria-live` discrète et ne déplacer le focus que si l’utilisateur a déclenché le chargement lui-même.
Si la liste est vraiment un flux d’articles, le rôle `feed` peut être pertinent; pour un catalogue de produits ou une grille de cartes, je garde souvent une structure plus simple avec une liste sémantique et un bouton Charger plus en secours. Ce petit détail change beaucoup de choses: il offre une sortie claire quand le chargement automatique devient fatigant ou imprévisible.
- Ne vole pas le focus quand un nouveau lot s’ajoute automatiquement.
- Annonces courtes et utiles : “12 nouveaux éléments chargés” suffit souvent.
- Prévois une alternative manuelle pour les utilisateurs clavier et pour les cas limites.
- Respecte `prefers-reduced-motion` si tes squelettes, transitions ou loaders bougent trop.
- Permets de revenir au haut de page sans effort excessif, surtout sur les listes longues.
Une interface qui charge bien mais qui n’est pas lisible reste une mauvaise interface. Une fois ce socle posé, il faut encore vérifier ce que la mécanique coûte réellement au navigateur, surtout quand la liste grandit.
Stabiliser les performances quand la liste grandit
Comme le rappelle web.dev, le vrai risque visible avec ce type de flux est souvent le décalage de mise en page. Si les cartes arrivent avec des tailles imprévisibles, si les images n’ont pas de dimensions réservées ou si le pied de page est repoussé en permanence, l’expérience se dégrade immédiatement. Le premier réflexe est donc de réserver l’espace avant le rendu final, avec des squelettes de taille réaliste ou des rapports largeur/hauteur déjà connus.
Ensuite, je surveille trois choses: la stabilité visuelle, la mémoire et la quantité de nœuds DOM. Quand la liste devient longue, le problème n’est plus seulement le fetch; c’est aussi tout ce que le navigateur garde en mémoire pour afficher des éléments invisibles. Dans ce cas, la virtualisation devient utile: on ne rend que la fenêtre visible et quelques éléments autour, puis on recycle le reste.
- Réserve la hauteur des cartes pour éviter les sauts de contenu.
- Charge les images paresseusement et fixe leurs dimensions dès que possible.
- Virtualise au-delà de quelques centaines d’éléments si la page reste ouverte longtemps.
- Mesure CLS, LCP et mémoire plutôt que de juger à l’œil seulement.
- Évite de tout virtualiser si l’utilisateur doit rechercher dans la page avec `Ctrl+F` ou copier du texte.
La virtualisation n’est pas un réflexe automatique. Je l’applique quand la liste commence à coûter trop cher, pas par principe. Pour le SEO et l’indexation, il faut encore une autre discipline, parce qu’un flux agréable à l’écran peut rester invisible pour un moteur de recherche.
Conserver une indexation propre sans casser le flux
Google Search Central recommande de garder une série paginée en parallèle du flux continu pour que chaque lot reste accessible au crawl. C’est le point que beaucoup d’équipes négligent: si tout dépend du scroll, le contenu devient difficile à découvrir, à partager et parfois même à retrouver dans les résultats. En pratique, je veux au minimum une URL stable par page ou par tranche, et un premier rendu qui expose déjà le cœur du contenu.
Je traite donc le défilement continu comme une couche d’ergonomie, pas comme l’unique source de vérité. La version paginée sert à l’exploration par les moteurs, aux liens directs et aux utilisateurs qui préfèrent un repère fixe. Le flux, lui, sert à la lecture rapide. Quand les deux coexistent, l’interface reste souple sans devenir opaque.
- Expose le premier lot dans le HTML initial ou via un rendu serveur.
- Garde des URLs partageables pour les segments importants de la liste.
- Évite de masquer tout le contenu derrière le JavaScript si l’indexation compte.
- Ne sacrifie pas les repères si la page contient un footer, des mentions légales ou des liens d’aide.
- Réserve le flux continu aux contenus où la découverte prime sur la consultation précise.
Le bon modèle dépend donc moins de la mode que de la tâche réelle. Si je dois aider quelqu’un à parcourir rapidement un flux, je laisse le défilement continu faire son travail; si je dois l’aider à revenir, comparer, citer ou partager, je réintroduis volontairement des repères plus nets.
Le compromis que je choisis le plus souvent en production
Dans les projets sérieux, je finis rarement avec un “tout ou rien”. Le compromis le plus solide consiste souvent à combiner un chargement automatique sur les premiers écrans, puis un bouton Charger plus ou une pagination explicite quand l’utilisateur a déjà parcouru plusieurs lots. On garde ainsi la fluidité au début, sans enfermer la fin du parcours dans une boucle sans repère.
Je recommande ce schéma quand le contenu doit rester confortable pour la découverte, mais aussi raisonnable pour l’accès, le partage et la maintenance. Pour un catalogue, c’est souvent la meilleure voie. Pour un flux éditorial dense, c’est une sécurité utile. Pour une page où chaque élément compte et doit être retrouvable, je reviens franchement à la pagination classique.
- Flux social ou inspiration : défilement continu avec sortie claire et pagination cachée côté technique.
- Catalogue produit : bouton intermédiaire ou pagination, surtout si la comparaison est centrale.
- Liste éditoriale ou documentaire : pagination prioritaire, flux continu seulement en option.
Mon critère final reste simple: si l’utilisateur doit surtout avancer, je privilégie le flux; s’il doit surtout retrouver, je privilégie les repères. Quand les deux besoins existent, je les fais cohabiter plutôt que de forcer une seule logique partout.