
Les endpoints API sont les points d’entrée concrets par lesquels un backend expose ses ressources et ses actions. Dans cet article, je vais clarifier ce que recouvre vraiment un endpoint, comment le structurer proprement, quelles méthodes HTTP lui donnent du sens et quels choix évitent les API confuses, fragiles ou difficiles à faire évoluer.
Je pars d’une idée simple : un bon endpoint n’est pas seulement une URL qui “marche”, c’est un contrat lisible pour le client, cohérent pour l’équipe backend et suffisamment stable pour durer.
L’essentiel à retenir sur les endpoints d’une API
- Un endpoint combine une ressource, une URL et une méthode HTTP, pas seulement un chemin.
- Je nomme les ressources avec des noms, pas avec des verbes, et je garde les chemins courts.
- La méthode HTTP porte le sens métier :
GET,POST,PUT,PATCHetDELETEne servent pas au même usage. - Les filtres, le tri et la pagination vont plutôt dans la query string que dans l’URL elle-même.
- La sécurité, les codes d’erreur et le versioning font partie de la qualité d’un endpoint, pas d’un détail d’implémentation.
Ce qu’un endpoint représente vraiment dans une API
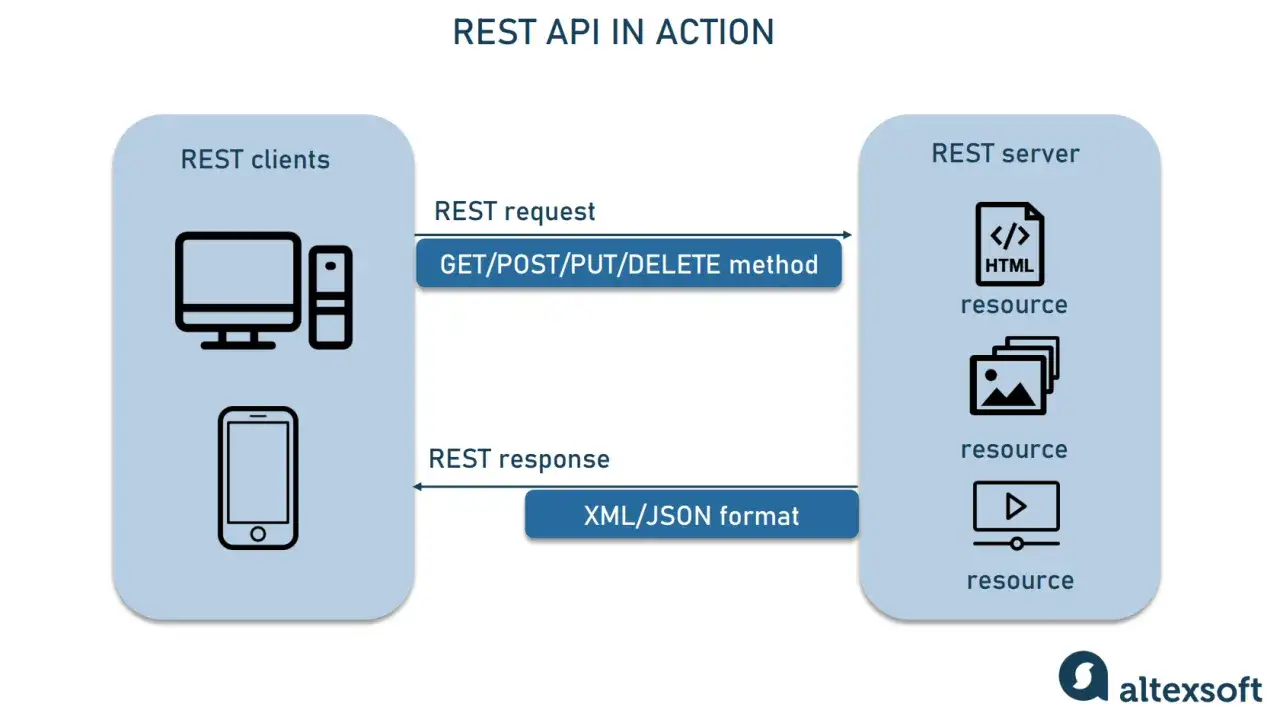
Quand je parle d’un endpoint, je parle d’un point d’accès précis à une ressource ou à une action exposée par l’API. En pratique, c’est l’association entre une URL et une méthode HTTP, par exemple GET /users/42 ou POST /orders. L’URL seule ne raconte pas toute l’histoire : la méthode change complètement le sens de la requête.
Cette nuance compte beaucoup côté backend. Une même route peut répondre à plusieurs méthodes, avec des comportements différents. GET /users/42 lit une ressource, PATCH /users/42 la modifie partiellement, DELETE /users/42 la supprime. C’est pour cela que je préfère raisonner en termes de ressources et d’opérations, pas seulement en termes de chaînes de caractères.
Il faut aussi distinguer le vocabulaire. Dans beaucoup de frameworks, une route est le mécanisme interne qui fait correspondre une URL à un handler. Un endpoint, lui, désigne davantage l’interface publique consommée par le client. Cette différence est légère dans le code, mais utile dès qu’on documente l’API, qu’on la versionne ou qu’on la confie à d’autres équipes.
Une bonne API repose donc sur des ressources identifiables, des méthodes cohérentes et des réponses prévisibles. Une fois cette base claire, le vrai sujet devient la manière de les nommer et de les organiser sans créer une surface d’accès illisible.
Comment je structure les chemins pour garder une API lisible
Je pars presque toujours des noms de ressources, pas des actions. Autrement dit, je préfère /users, /orders ou /articles à des chemins comme /getUsers ou /createOrder. Le verbe est déjà porté par la méthode HTTP, donc le mettre dans l’URL ajoute du bruit sans apporter de valeur.
Je fais aussi attention à la profondeur des chemins. Deux niveaux suffisent dans la majorité des cas. Au-delà, on commence souvent à reproduire des détails d’implémentation plutôt que des besoins métier. Par exemple, /users/42/orders reste lisible, mais /users/42/orders/2026/items/3/details est déjà un signal d’alarme.
| Forme moins claire | Version plus propre | Pourquoi ça marche mieux |
|---|---|---|
GET /getUsers |
GET /users |
La méthode HTTP dit déjà qu’on lit des données. |
POST /createOrder |
POST /orders |
L’intention est portée par POST, pas par un verbe dans le chemin. |
GET /users/42/orders/last/paid |
GET /users/42/orders?status=paid&limit=1 |
Le filtrage et la limite relèvent mieux de la query string. |
GET /api/v1/userProfile |
GET /api/v1/users/42 |
Le nom de ressource reste cohérent et prévisible. |
Je garde aussi en tête que la structure publique de l’API n’a pas à refléter exactement la structure interne de la base de données. C’est particulièrement vrai avec une base NoSQL, où la tentation est forte d’exposer directement des collections ou des documents. En pratique, je préfère une API pensée pour le consommateur, puis une couche d’adaptation côté backend. C’est elle qui protège la stabilité de l’interface quand le modèle de données évolue.
Enfin, je sépare nettement ce qui appartient au chemin et ce qui appartient aux paramètres. Le chemin identifie une ressource. Les filtres, le tri, la recherche et la pagination s’expriment mieux dans la query string, par exemple ?page=2&limit=20&sort=-createdAt. Cette discipline évite les URLs trop longues et les conventions improvisées. Une structure propre ne vaut toutefois rien si la méthode HTTP raconte autre chose que l’intention du serveur.
Les méthodes HTTP qui donnent du sens aux endpoints
Je traite les méthodes HTTP comme le langage de l’API. Elles ne sont pas interchangeables. Un endpoint bien conçu devient beaucoup plus clair dès qu’on respecte la sémantique de chaque méthode, surtout sur des projets qui doivent durer et être consommés par plusieurs clients.
| Méthode | Usage principal | Propriété utile | Exemple |
|---|---|---|---|
GET |
Lire une ressource ou une collection | Safe, pas d’effet de bord attendu | GET /articles/12 |
POST |
Créer une ressource ou déclencher un traitement | Souple, mais souvent non idempotent | POST /articles |
PUT |
Remplacer une ressource complète | Idempotent | PUT /articles/12 |
PATCH |
Modifier partiellement une ressource | Pratique pour les mises à jour ciblées | PATCH /articles/12 |
DELETE |
Supprimer une ressource | Idempotent dans sa logique métier | DELETE /articles/12 |
Deux détails comptent souvent plus qu’on ne le pense. D’abord, GET sert à récupérer une représentation d’une ressource et ne devrait pas embarquer de logique cachée. Ensuite, PUT et PATCH ne racontent pas la même chose : le premier remplace, le second ajuste. Je vois encore trop d’équipes utiliser POST pour tout faire, puis compenser avec des conventions floues côté payload. C’est confortable au départ, mais cela crée vite des contrats imprévisibles.
Je garde aussi un œil sur les cas spécifiques comme HEAD ou OPTIONS, surtout dès qu’il y a du cache, du CORS ou des intégrations plus fines. Pour un produit classique, ils ne sont pas centraux, mais ils deviennent utiles quand l’API doit être observée, optimisée ou intégrée proprement. À partir de là, il faut passer des règles de forme aux usages concrets.
Construire une API autour des usages métier
Un bon backend ne se contente pas d’exposer des données. Il expose des parcours cohérents. Quand je dessine des endpoints, je pars des objets métier que le client manipule réellement, puis je vérifie que chaque ressource a une place claire dans l’ensemble.
Prenons un site de contenu. Je vais souvent structurer les accès autour de quelques blocs simples :
-
GET /articlespour lister les contenus. -
GET /articles/{id}pour afficher un article précis. -
POST /articlespour créer un article. -
PATCH /articles/{id}pour modifier un titre, un statut ou une catégorie. -
GET /articles/{id}/commentspour récupérer les commentaires liés.
Le point important ici, ce n’est pas seulement la forme. C’est la logique métier derrière la forme. Une collection donne la vue d’ensemble, une ressource unique donne le détail, une sous-ressource exprime une relation forte. Quand je perds cette hiérarchie, je finis souvent avec une API qui ressemble à une liste de fonctions déguisées.
Je fais aussi attention aux endpoints d’action, comme /auth/login, /auth/refresh ou /orders/{id}/cancel. Ils ne sont pas un échec du design REST. Ils répondent simplement à des opérations qui ne se réduisent pas à un CRUD strict. La bonne question n’est pas “est-ce un verbe ?”, mais “est-ce l’expression la plus claire du besoin métier ?”.
Dans un produit réel, il faut aussi gérer la pagination, la recherche et les filtres. Je recommande de stabiliser ces conventions tôt, par exemple avec ?page=1&limit=20, ?sort=-createdAt ou ?status=published. Cela évite les variations sauvages entre endpoints similaires et aide énormément les clients front, mobile ou partenaires. Dès qu’une API sort du cercle interne, la sécurité et la stabilité deviennent des critères de conception, pas de simple exploitation.
Sécurité, erreurs et versioning ne sont pas accessoires
Pour moi, un endpoint n’est pas vraiment fini tant que je n’ai pas répondu à trois questions : qui peut l’appeler, que se passe-t-il en cas d’erreur et comment je le ferai évoluer sans casser les clients. C’est là que beaucoup d’API paraissent correctes en développement, puis deviennent coûteuses à maintenir.
Côté sécurité, je vérifie systématiquement l’authentification et l’autorisation au niveau du bon périmètre. L’erreur classique consiste à sécuriser “l’API” en bloc alors qu’il faut raisonner endpoint par endpoint, parfois même action par action. Un utilisateur peut être autorisé à lire une ressource sans être autorisé à la supprimer. Cela paraît évident, mais c’est un point de fuite fréquent.
Je garde aussi une politique stricte sur les erreurs. Les codes HTTP doivent rester cohérents avec la cause réelle :
-
400pour une requête invalide. -
401si l’authentification manque ou échoue. -
403si l’utilisateur n’a pas le droit d’agir. -
404si la ressource n’existe pas ou ne doit pas être révélée. -
409en cas de conflit, par exemple une ressource déjà existante. -
422quand la structure est correcte mais que la validation métier échoue. -
429si le client dépasse une limite de requêtes.
Un bon payload d’erreur est court, stable et lisible par une machine. Je préfère généralement une structure avec un code interne, un message explicite et, si nécessaire, des détails sur les champs en cause. Cela facilite le débogage côté front sans révéler trop d’informations techniques.
Le versioning mérite la même rigueur. Sur une API publique, je privilégie souvent un préfixe explicite comme /v1, surtout si les consommateurs ont des cycles de mise à jour lents. Cela permet d’introduire une nouvelle version sans casser l’ancienne. Les endpoints expérimentaux ou en préversion doivent rester clairement séparés des routes stables, sinon on finit avec des clients qui dépendent d’une surface encore mouvante. Avant de publier, je fais une dernière vérification très pragmatique.
La grille que j’utilise avant de mettre des endpoints en production
Quand je relis une API avant livraison, je ne cherche pas d’abord l’élégance théorique. Je vérifie la robustesse pratique. Cette grille me permet de repérer rapidement les erreurs qui coûtent cher plus tard :
- Le chemin décrit-il une ressource réelle, pas une action déguisée ?
- La méthode HTTP correspond-elle au comportement attendu ?
- Les filtres, le tri et la pagination sont-ils dans la query string ?
- Les réponses sont-elles cohérentes sur toute la famille d’endpoints ?
- Les erreurs sont-elles documentées et stables ?
- La sécurité est-elle appliquée au bon niveau, sans exception implicite ?
- Le contrat est-il assez clair pour qu’un autre développeur l’utilise sans deviner ?
- La version de l’API peut-elle évoluer sans forcer une rupture immédiate ?
Je recommande aussi de tester les endpoints comme un vrai consommateur le ferait, avec des cas normaux et des cas limites : valeur manquante, payload incomplet, doublon, ressource absente, accès refusé, surcharge. Une API qui résiste bien à ces situations est généralement plus saine qu’une API qui ne marche qu’avec des requêtes idéales. Si je devais résumer la logique en une phrase, je dirais qu’un bon endpoint doit être simple à lire, difficile à mal utiliser et stable dans le temps.