
Le lien entre un nom de domaine et une adresse IP paraît simple tant qu’il ne faut pas migrer un service, faire un rollback ou diagnostiquer une panne de résolution. En pratique, tout se joue entre les enregistrements DNS, les caches et le tempo de propagation. En DevOps, bien comprendre ce mécanisme évite des déploiements imprévisibles, des coupures évitables et des erreurs de routage difficiles à lire.
En pratique, le DNS relie un nom lisible à une IP, puis les caches déterminent la vitesse des changements
- Le DNS traduit un nom de domaine en adresse IP pour que les machines sachent où se connecter.
- Un enregistrement A pointe vers une IPv4, un AAAA vers une IPv6, un CNAME vers un autre nom, et un PTR fait l’inverse.
- Le TTL contrôle la durée de mise en cache: plus il est court, plus les changements arrivent vite, mais plus le volume de requêtes augmente.
- En DevOps, je privilégie les noms de domaine dans les configurations, pas les IP figées, surtout quand l’infrastructure bouge.
- Le reverse DNS reste utile pour l’email sortant, l’observabilité et certains contrôles de réputation.
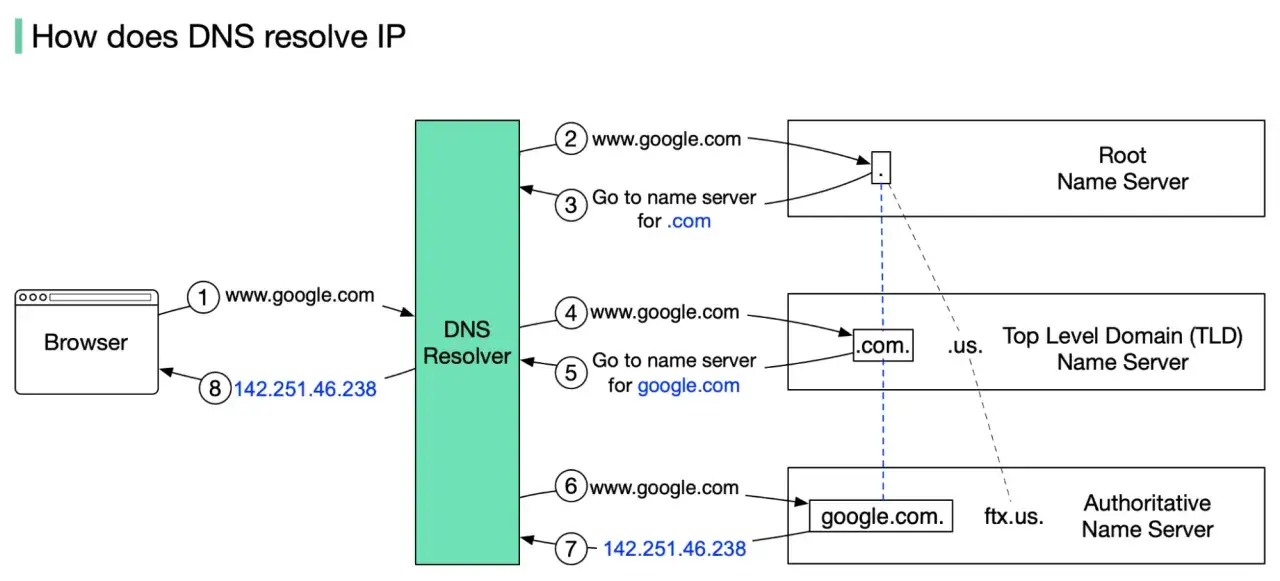
Comment un nom de domaine devient une adresse IP
Je résume souvent le DNS ainsi: l’humain tape un nom, la machine reçoit une adresse. Quand un navigateur demande un site, il interroge d’abord un résolveur récursif, qui vérifie son cache puis, si nécessaire, remonte vers les serveurs faisant autorité pour obtenir la réponse officielle de la zone.
Le chemin classique est assez court, mais il explique beaucoup de choses en production:
- Le client demande quel IP correspond à ce nom.
- Le résolveur cherche dans ses caches locaux et réseau.
- S’il n’a pas la réponse, il interroge la hiérarchie DNS jusqu’au serveur autoritaire.
- Le serveur renvoie l’adresse IP, et le client se connecte ensuite à cette IP via TCP, TLS, HTTP ou QUIC.
Le point à retenir est simple: le DNS ne transporte pas votre application, il indique seulement où la joindre. C’est aussi pour cela qu’un même nom peut renvoyer plusieurs IP, par exemple pour répartir la charge ou pour accompagner une architecture multi-région. Une fois ce mécanisme clair, les types d’enregistrements deviennent beaucoup plus lisibles.
Les enregistrements DNS à connaître pour travailler proprement
Quand je veux éviter les confusions entre nom, adresse et rôle réseau, je commence par les enregistrements de base. Ils ne servent pas tous au même moment, mais ils racontent tous une partie du lien entre le domaine et l’IP.
| Enregistrement | Rôle | Ce qu’il pointe | Quand je l’utilise | Point d’attention |
|---|---|---|---|---|
| A | Associe un nom à une adresse | IPv4 | Site web, API, service exposé en IPv4 | Un A seul ne couvre pas IPv6 |
| AAAA | Associe un nom à une adresse | IPv6 | Services accessibles en IPv6 | À maintenir en cohérence avec le A si vous êtes en dual-stack |
| CNAME | Crée un alias vers un autre nom | Un autre nom de domaine | Aliases, sous-domaines, indirection | Il ne pointe pas vers une IP directement et n’est pas toujours accepté à la racine du domaine |
| PTR | Fait la résolution inverse | Un nom associé à une IP | Reverse DNS, email sortant, diagnostic | Il dépend du bloc IP, pas seulement du nom de domaine |
| NS | Délègue l’autorité d’une zone | Serveurs DNS autoritaires | Découpage de zones, changement de fournisseur DNS | Une modification NS se traite avec prudence, car elle peut mettre du temps à se généraliser |
Dans les projets mixtes IPv4/IPv6, je conseille presque toujours de garder A et AAAA alignés, sauf si l’un des deux réseaux n’est vraiment pas disponible. Et si votre fournisseur DNS propose un équivalent de CNAME flattening à la racine, ce n’est pas un détail cosmétique: c’est une manière de contourner les limites du CNAME pur tout en gardant une indirection propre. Le sujet suivant, c’est la vitesse à laquelle ces réponses changent dans le monde réel.
Pourquoi le TTL change la vitesse de vos déploiements
Le TTL, c’est le minuteur de la mémoire DNS. Il indique pendant combien de temps un résolveur peut réutiliser une réponse sans redemander l’information à la source. En clair, plus le TTL est long, plus les réponses sont stables et peu coûteuses à servir; plus il est court, plus les changements arrivent vite, mais plus vous payez en requêtes et en bruit réseau.
Selon AWS Route 53, la plage recommandée va de 60 à 172 800 secondes. Dans la pratique, je vois souvent trois cas de figure:
| Situation | TTL courant | Pourquoi |
|---|---|---|
| Bascule rapide ou failover | 60 à 120 s | Réduire le temps d’attente entre l’ancien point de terminaison et le nouveau |
| Service stable en production | 3 600 à 86 400 s | Limiter la charge DNS et profiter d’un cache efficace |
| Enregistrements rarement modifiés, comme certaines délégations | Plusieurs heures à un jour | Les changements sont rares, donc le cache a plus d’intérêt que la réactivité |
Ma règle pratique est simple: je baisse le TTL avant une migration, pas pendant la migration. Ensuite, une fois la bascule validée et les anciens clients purgés, je le remonte pour retrouver de la stabilité. C’est un détail banal sur le papier, mais en incident il peut faire la différence entre quelques minutes de transition et une heure de confusion. Cette logique devient encore plus importante quand le DNS fait partie d’une chaîne DevOps plus large.
Ce que cela change dans une chaîne DevOps
Dans un environnement DevOps, le DNS n’est pas un simple annuaire. C’est une couche d’abstraction qui protège vos déploiements contre les IP mouvantes, les environnements éphémères et les changements de fournisseur. Je préfère presque toujours une configuration qui référence un nom stable plutôt qu’une IP gravée en dur dans le code ou dans un fichier de configuration.
- Déploiements cloud : les IP d’instances, de pods ou de conteneurs changent vite, alors que le nom de service reste stable.
- Blue-green et canary : le DNS peut aider à basculer, mais il reste trop grossier pour une granularité très fine; pour cela, un load balancer ou une couche de trafic dédiée est souvent plus fiable.
- Infrastructure as Code : garder les zones DNS dans Terraform, CloudFormation ou un autre système de versioning facilite les revues, les rollbacks et l’audit.
- DNS interne et public : séparer les deux évite de mélanger les besoins des utilisateurs externes et ceux des services internes.
- Service discovery : dans Kubernetes ou dans une architecture microservices, le nom de service vaut souvent plus que l’adresse IP du moment.
Je vois souvent une erreur de conception: vouloir faire porter au DNS un rôle de routage ultra-précis. Ce n’est pas sa vocation. Le DNS donne une direction, puis les caches, les résolveurs et parfois un CDN ou un load balancer complètent le travail. Cette limite explique une grande partie des incidents que j’observe en production, surtout quand l’équipe suppose qu’un changement sera visible immédiatement partout.
Les erreurs que je vois le plus souvent en production
Quand un projet grandit, les problèmes ne viennent pas du concept DNS lui-même, mais de la manière dont on l’utilise. Les mêmes erreurs reviennent avec une régularité étonnante.
- Coder une IP en dur : la première migration casse la configuration, surtout quand l’infrastructure est autoscalée ou réallouée.
- Oublier l’IPv6 : un A seul fonctionne encore dans beaucoup de cas, mais un AAAA manquant peut créer des comportements incohérents selon les réseaux.
- Changer un enregistrement sans préparer le TTL : si le cache est long, une partie des utilisateurs restera sur l’ancienne adresse bien après votre changement.
- Utiliser le DNS pour une bascule trop fine : le contrôle est trop approximatif pour du trafic au niveau milliseconde ou pour un arbitrage utilisateur par utilisateur.
- Ignorer les caches hors DNS : navigateur, système d’exploitation, runtime applicatif ou proxy peuvent conserver une réponse au-delà de ce que vous attendez.
- Confondre résolution et sécurité : le fait qu’un nom pointe vers une IP ne prouve rien sur l’identité du service derrière.
Le piège le plus coûteux, à mes yeux, reste l’idée que tout serait instantané. Le DNS est fiable précisément parce qu’il cache et distribue, pas parce qu’il change immédiatement. Et c’est là qu’un autre sujet, souvent négligé, prend de la valeur: le reverse DNS.
Le reverse DNS compte encore pour l’email et l’exploitation
La résolution inverse fait le chemin opposé: elle part d’une IP pour retrouver un nom. Techniquement, elle repose sur des PTR records, généralement publiés dans les zones in-addr.arpa pour IPv4 et ip6.arpa pour IPv6. En pratique, ce n’est pas juste un détail de réseau; c’est un signal utile pour l’email sortant, les outils de diagnostic et certains mécanismes de réputation.
- le PTR de l’IP,
- le nom qui répond en A ou AAAA,
- le nom utilisé dans la bannière SMTP ou le HELO/EHLO.
Quand ces trois éléments racontent la même histoire, la maintenance devient plus simple et les outils de sécurité lisent votre infrastructure avec moins d’ambiguïté. Ce n’est pas spectaculaire, mais c’est exactement le genre de cohérence qui évite des tickets pénibles à 2 heures du matin.
Le réflexe que j’applique avant une bascule DNS
Avant toute modification sensible, je traite le DNS comme une vraie étape de livraison. Je commence par vérifier les enregistrements A, AAAA, CNAME et PTR concernés, puis je m’assure que le TTL est compatible avec le délai de retour arrière que je veux me garder. Ensuite, je teste la résolution depuis plusieurs points de vue, pas seulement depuis ma machine locale.
- Je contrôle la cohérence entre ancien et nouveau point de terminaison.
- Je réduis le TTL suffisamment tôt pour que la fenêtre de transition soit réaliste.
- Je valide la résolution avec plusieurs résolveurs et depuis plusieurs réseaux.
- Je garde l’ancien service disponible jusqu’à ce que les caches les plus lents aient expiré.
Si je devais résumer toute la logique en une seule phrase, ce serait celle-ci: le nom rend l’infrastructure lisible pour l’humain, l’IP la rend joignable pour la machine, et le TTL décide à quelle vitesse cette relation peut changer. En le traitant comme une brique d’architecture, et pas comme un simple paramètre de panneau d’administration, on gagne en stabilité, en prévisibilité et en confort d’exploitation.