
Une branche Git sert à isoler un travail sans casser la ligne principale du projet. Pour une équipe web ou DevOps, c’est ce qui permet d’avancer sur une fonctionnalité, corriger un incident ou préparer une livraison sans bloquer le reste du dépôt. Dans cet article, j’explique comment une branche fonctionne réellement, comment la créer et la fusionner proprement, puis comment choisir un workflow qui reste lisible quand plusieurs personnes contribuent.
Les points à garder en tête avant de créer la moindre branche
- Une branche est un pointeur léger sur des commits, pas une copie complète du dépôt.
-
git switch -cest la manière la plus claire de démarrer un travail isolé. -
mergeconserve la structure des branches, alors querebaseréécrit l’historique. - Les branches courtes s’intègrent mieux aux tests automatisés et aux déploiements continus.
- Le bon workflow dépend surtout du rythme de livraison et du niveau d’automatisation.
- Supprimer les branches fusionnées garde un dépôt lisible et réduit le bruit.
Ce qu’une branche change vraiment dans Git
Dans Git, une branche n’est pas une copie séparée du projet. C’est un repère mobile qui pointe vers un commit, et ce repère avance à chaque nouveau commit sur cette ligne de développement. La branche active est celle vers laquelle pointe HEAD ; quand je valide une modification, Git déplace simplement ce pointeur.
Cette mécanique explique pourquoi les branches sont si pratiques. Je peux lancer une branche pour une correction urgente, une expérimentation de backend ou un chantier front sans perturber la branche principale. Tant que je reste sur une branche isolée, le reste de l’équipe garde un dépôt stable, ce qui compte énormément quand les déploiements sont fréquents.
On parle souvent de branche de fonctionnalité, de correctif ou de release. Le nom change, mais l’idée reste la même : séparer un sujet pour mieux le tester, le relire et le livrer. Quand on comprend ce point, les commandes Git cessent d’être mécaniques et deviennent un vrai outil de pilotage.
Créer et manipuler des branches sans perdre le fil
Je préfère les commandes modernes de Git, parce qu’elles sont plus lisibles que l’ancien réflexe autour de checkout. Pour démarrer un travail, j’utilise généralement git switch -c ; pour revenir sur la branche principale, git switch main ou le nom de branche adopté par l’équipe.
| Commande | Ce qu’elle fait | Quand je l’utilise |
|---|---|---|
git branch |
Liste les branches locales | Voir rapidement ce qui existe dans le dépôt |
git branch -vv |
Liste les branches avec les infos de suivi | Vérifier où en est chaque branche avant un push ou un merge |
git switch -c feature/paiement |
Crée une branche et bascule dessus | Démarrer un sujet proprement sans toucher à la branche principale |
git switch main |
Change de branche | Revenir à la base avant une mise à jour ou une fusion |
git branch -m ancien nouveau |
Renomme une branche | Corriger tôt un nom mal choisi |
git branch -d feature/paiement |
Supprime une branche déjà fusionnée | Nettoyage normal après intégration |
git branch -D feature/paiement |
Supprime une branche de force | Uniquement pour une branche jetable ou ratée |
Pour les références distantes devenues mortes, git fetch --prune nettoie les noms obsolètes et évite que des branches supprimées continuent d’apparaître partout. Je trouve ce geste simple, mais il change vite la lisibilité d’un dépôt un peu ancien.
Pour le nommage, je reste simple et prévisible : feature/paiement, bugfix/connexion, hotfix/inc-502. Les préfixes aident à filtrer les branches dans un projet réel, surtout quand plusieurs développeurs travaillent en parallèle. J’évite les noms vagues ou les mélanges de sujets, parce qu’une branche qui ne dit plus ce qu’elle contient finit toujours par traîner plus longtemps que prévu.
Une fois que la création et le nommage sont clairs, la vraie question devient celle de l’intégration : comment fusionner sans casser l’historique ni la cadence de livraison.
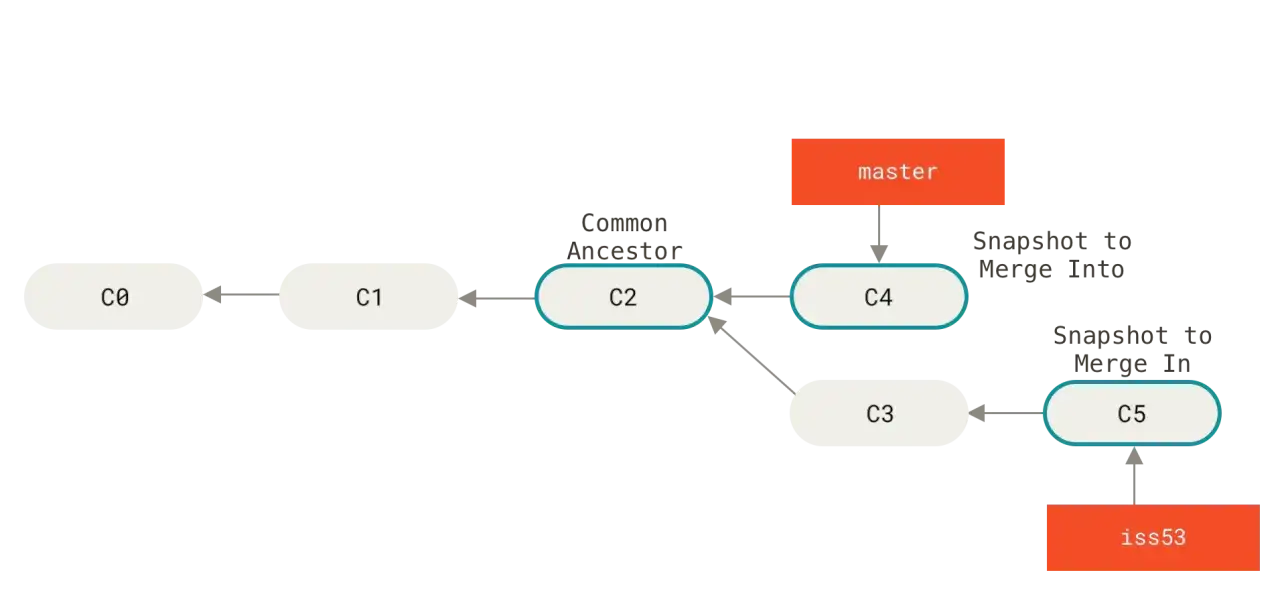
Fusionner sans casser l’historique
Le choix entre merge et rebase dépend moins de la théorie que du contexte d’équipe. Je résume les différences de cette façon : merge préserve les branches telles qu’elles ont vécu, tandis que rebase réécrit une suite de commits pour la rendre linéaire.
| Méthode | Ce qu’elle fait | Point fort | Limite | Quand je la choisis |
|---|---|---|---|---|
merge |
Combine deux historiques sans les réécrire | Garde la trace réelle du travail en parallèle | Ajoute parfois un commit de fusion | Branches partagées ou intégrations d’équipe |
fast-forward |
Avance simplement le pointeur de la branche cible | Historique très propre et sans commit supplémentaire | Impossible si les branches ont divergé | Branche courte, sans divergence réelle |
rebase |
Rejoue les commits sur une nouvelle base | Historique linéaire, facile à lire | Réécrit les identifiants de commit | Branche locale ou encore privée |
Le point sensible, c’est l’historique public. Je déconseille de rebaser une branche déjà partagée avec d’autres personnes, parce que cela change les identifiants des commits et peut faire perdre du temps à toute l’équipe. Pour une branche locale ou une branche de travail encore privée, le rebase peut au contraire garder un historique plus lisible.
-
git statuspour voir ce qui bloque. - Ouvrir les fichiers concernés et résoudre les marqueurs de conflit.
-
git addpour valider la résolution. -
git merge --continueougit rebase --continueselon le cas. - Relancer les tests avant de pousser.
Cette rigueur évite les intégrations « rapides » qui reviennent ensuite en bug de production. C’est là que le lien avec DevOps devient concret : une branche n’a de valeur que si elle s’insère proprement dans la chaîne de test et de déploiement.
Adapter les branches au rythme DevOps de l’équipe
Dans une organisation DevOps, la branche n’est pas seulement un outil de versionnement ; elle devient un point d’entrée pour la revue, la CI et parfois le déploiement d’environnements de préproduction. Dès que la branche est poussée sur le dépôt distant, j’essaie de l’attacher à sa branche amont avec git push -u origin feature/paiement : ensuite, les opérations de suivi sont plus simples et plus cohérentes.
Les branches distantes de suivi servent de miroir à l’état du serveur. On ne les déplace pas à la main ; Git les met à jour lors des échanges réseau. C’est utile pour comprendre ce qui a changé chez les autres sans toucher à leur travail.
| Workflow | Idée simple | Points forts | Limites | Je le recommande quand |
|---|---|---|---|---|
| Git Flow | Branches longues avec develop, release et hotfix
|
Structure forte et séparation nette des étapes | Plus lourd à maintenir et plus lent à faire vivre | Produits à cycles de release planifiés ou versions parallèles |
| GitHub Flow | Une branche courte part de main, passe en revue puis revient vite |
Simple, clair et très compatible avec la CI | Demande une vraie discipline sur les tests et les revues | Équipes web, SaaS et livraisons fréquentes |
| Trunk-based development | Branches très courtes, voire commits fréquents vers la branche principale, avec feature flags | Réduit la divergence et favorise la livraison continue | Exige une automation solide et une bonne couverture de tests | Équipes matures en CI/CD qui déploient souvent |
Mon expérience est assez simple ici : pour un site web, une API ou un produit livré souvent, je privilégie généralement un modèle proche de GitHub Flow ou du trunk-based development. Git Flow reste défendable quand les cycles de release sont plus formels ou quand plusieurs versions doivent cohabiter, mais il ajoute de la structure qu’il faut vraiment justifier. Le bon modèle est celui que l’équipe applique sans ambiguïté, pas celui qui paraît le plus élégant sur le papier.
Quand les branches sont courtes, les revues sont plus simples, les conflits diminuent et la CI donne un signal plus fiable. Cette logique fonctionne d’autant mieux si la suite du projet est disciplinée, ce qui m’amène aux erreurs que je vois le plus souvent.
Les erreurs qui coûtent du temps en équipe
- Garder une branche trop longtemps. Plus la branche vieillit, plus l’écart avec la base grandit, et plus la fusion devient coûteuse.
- Rebasing une branche déjà partagée. C’est le meilleur moyen de créer de la confusion sur les commits déjà consultés par d’autres.
- Mélanger plusieurs sujets dans la même branche. Une fonctionnalité, un correctif ou un refactor doivent rester lisibles séparément.
- Pousser sans test ni revue. La branche n’est pas une excuse pour contourner la qualité ; elle sert justement à la protéger.
- Oublier de nettoyer les branches fusionnées. Le dépôt devient vite bruyant, et les vraies branches utiles se perdent dans la liste.
- Choisir des noms flous. Un nom précis fait gagner du temps à toute l’équipe, surtout quand on revient sur le sujet deux semaines plus tard.
Je vois souvent un autre piège plus subtil : la branche devient un espace de stockage pour du travail inachevé sans date de sortie. Dès qu’une branche sert de fourre-tout, elle cesse d’être un outil de livraison et devient une dette d’organisation.
Pour éviter ça, je préfère des branches petites, une seule intention par branche, et une règle simple de suppression après fusion. C’est moins spectaculaire qu’un workflow très sophistiqué, mais c’est nettement plus robuste au quotidien.
Le flux qui reste lisible quand les livraisons s’accélèrent
Si je devais résumer la discipline que je recommande le plus souvent, ce serait celle-ci : une branche principale protégée, des branches de travail courtes, des tests automatiques à chaque intégration et un nettoyage régulier des branches fermées. Ce cadre suffit déjà à éviter une grande partie des dérives que je vois dans les projets qui grossissent vite.
- Protéger la branche principale contre les pushes directs.
- Standardiser les préfixes de branches pour qu’elles soient immédiatement lisibles.
- Choisir une seule stratégie d’intégration et la documenter clairement.
- Supprimer les branches fusionnées dès qu’elles n’ont plus d’utilité.
- Compléter les branches courtes par des feature flags si la livraison continue est un objectif réel.
Au fond, une branche bien utilisée ne ralentit pas l’équipe : elle réduit le risque, clarifie le travail en cours et rend la livraison plus prévisible. C’est exactement ce que je cherche quand je travaille sur un projet web ou backend où chaque commit doit pouvoir passer proprement du poste local au pipeline puis à la production.